
Typhoon 2.1
Collection
Typhoon 2.1 Text ThaiLLM release by SCB 10X.
•
7 items
•
Updated
•
3
Typhoon2.1-Gemma3-12B: Thai Large Language Model (Instruct)
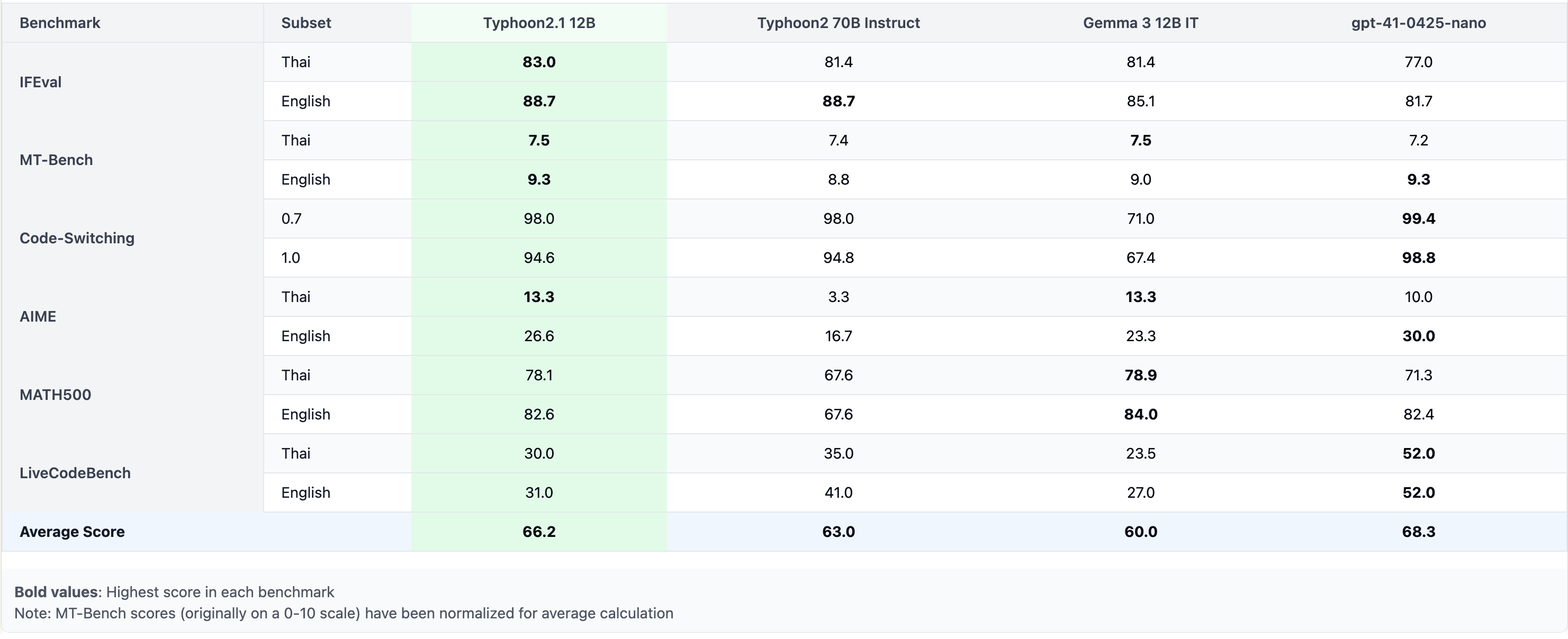
Typhoon2.1-Gemma3-12B is a instruct Thai 🇹🇭 large language model with 12 billion parameters, a 128K context length, and function-calling capabilities. It is based on Gemma3 12B.
This repo contains FP8 quantization of the original Typhoon2.1 12B model for more efficient deployment on NVIDIA Hopper and newer architectures.
Remark: This is text only model.
This section shows how to run Typhoon2.1 as an OpenAI-compatible API server using vllm.
pip install vllm
vllm serve scb10x/typhoon2.1-gemma3-12b-fp8 --max-model-len 16000 --dtype bfloat16 --tool-call-parser pythonic --enable-auto-tool-choice
# adjust --max-model-len based on your avaliable memory
You can provide tools to the vLLM-powered OpenAI-compatible API for functionality.
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco?"}],
tools=tools,
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")
Typhoon supports two modes: Non-thinking mode (default): Fast response generation without extra reasoning steps. Thinking mode: The model first reasons internally, then provides a clearer and potentially more accurate final answer. You can enable thinking mode by: Setting enable_thinking=True in apply_chat_template. Using a special system prompt that instructs the model to reason inside ... tags.
You can turn on thinking mode by either
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
You are a helpful assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state a response that addresses the user's request and aligns with their preferences, not just providing a direct answer.
{
"model": "scb10x/typhoon2.1-gemma3-12b",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"chat_template_kwargs": {"enable_thinking": true}
}
This section introduces budget forcing, an advanced technique to let the model spend more time and tokens reasoning before producing a final answer—great for improving performance on complex questions.
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
class BudgetForcingHandler:
def __init__(self, model_name: str, max_think_token: int, max_ignore=5, temperature=0.6, seed=32):
self.temperature = temperature
self.seed = seed
self.max_think_token = max_think_token
self.max_ignore = max_ignore
self.model = LLM(model_name, dtype='bfloat16', enforce_eager=True)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.alternative_str = '\nAlternatively'
self.system = """You are a reasoning assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state the final answer."""
def __call__(self, prompts: List[str]):
count_prompt = len(prompts)
prompts = [self.tokenizer.apply_chat_template([{'role': 'system', 'content': self.system}, {'role': 'user', 'content': f'Please solve this math question, and put your final answer within \\boxed{{}}.\n{p}'}], add_generation_prompt=True, tokenize=False) for p in prompts]
sampling_params = SamplingParams(
max_tokens=self.max_think_token,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params
)
outputs = [output.outputs[0].text for output in o]
token_count = [len(output.outputs[0].token_ids) for output in o]
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
for _ in range(self.max_ignore): # Num of times to skip stop token
inference_loop_prompts = []
inference_idx = []
max_inference_token = 0
print('current token count: ', token_count)
for i in range(len(prompts)):
left_budget = self.max_think_token - token_count[i]
if left_budget > 0:
prompts[i] = prompts[i] + self.alternative_str
inference_loop_prompts.append(prompts[i])
inference_idx.append(i)
if left_budget > max_inference_token:
max_inference_token = left_budget
outputs = ['' for _ in range(len(prompts))]
if max_inference_token == 0 or len(inference_loop_prompts) == 0:
break
sampling_params = SamplingParams(
max_tokens=max_inference_token,
min_tokens=1,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
inference_loop_prompts,
sampling_params=sampling_params
)
assert len(inference_idx) == len(inference_loop_prompts)
assert len(inference_idx) == len(o)
for i, output in zip(inference_idx, o):
outputs[i] = output.outputs[0].text
for i, idx in enumerate(inference_idx):
token_count[idx] = token_count[idx] + len(o[i].outputs[0].token_ids)
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
print('generating answer...')
prompts = [p + '\nTime\'s up. End of thinking process. Will answer immediately.\n</think>' for i, p in enumerate(prompts)]
sampling_params = SamplingParams(
max_tokens=2048,
min_tokens=0,
seed=self.seed,
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params,
)
for i in range(len(prompts)):
prompts[i] = prompts[i] + o[i].outputs[0].text
assert len(prompts) == count_prompt
return prompts
handler = BudgetForcingHandler("scb10x/typhoon2.1-gemma3-12b", max_think_token=2048)
handler(["How many r in raspberry?"])
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
https://twitter.com/opentyphoon
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}