
Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation (ICCV 2025)
Luca Barsellotti* Lorenzo Bianchi* Nicola Messina Fabio Carrara Marcella Cornia Lorenzo Baraldi Fabrizio Falchi Rita Cucchiara
Project Page | Paper | Code
About
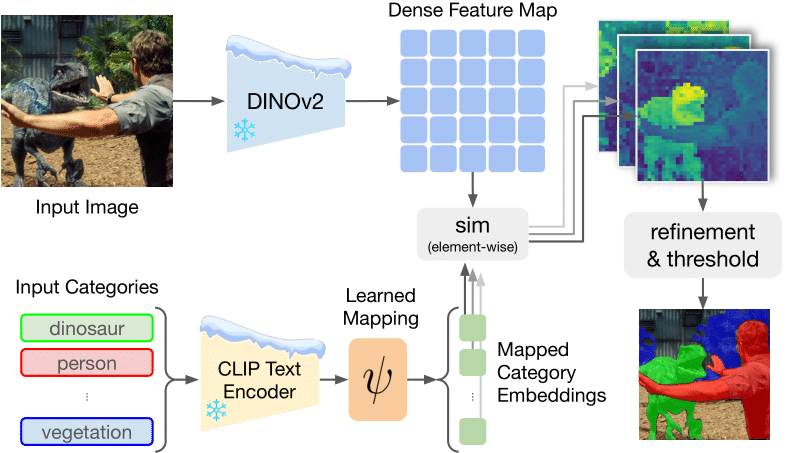
Open-Vocabulary Segmentation (OVS) aims at segmenting images from free-form textual concepts without predefined training classes. While existing vision-language models such as CLIP can generate segmentation masks by leveraging coarse spatial information from Vision Transformers, they face challenges in spatial localization due to their global alignment of image and text features. Conversely, self-supervised visual models like DINO excel in fine-grained visual encoding but lack integration with language. To bridge this gap, we present Talk2DINO, a novel hybrid approach that combines the spatial accuracy of DINOv2 with the language understanding of CLIP. Our approach aligns the textual embeddings of CLIP to the patch-level features of DINOv2 through a learned mapping function without the need to fine-tune the underlying backbones. At training time, we exploit the attention maps of DINOv2 to selectively align local visual patches with textual embeddings. We show that the powerful semantic and localization abilities of Talk2DINO can enhance the segmentation process, resulting in more natural and less noisy segmentations, and that our approach can also effectively distinguish foreground objects from the background. Experimental results demonstrate that Talk2DINO achieves state-of-the-art performance across several unsupervised OVS benchmarks.
Sample Usage
Mapping CLIP Text Embeddings to DINOv2 space with Talk2DINO
We can use Talk2DINO to map CLIP text embeddings into the DINOv2 patch embedding space.
import clip
from src.model import ProjectionLayer
import torch
import os
# Device setup
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Configuration and weights
proj_name = 'vitb_mlp_infonce'
config_path = os.path.join("configs", f"{proj_name}.yaml")
weights_path = os.path.join("weights", f"{proj_name}.pth")
# Load Talk2DINO projection layer
talk2dino = ProjectionLayer.from_config(config_path)
talk2dino.load_state_dict(torch.load(weights_path, map_location=device))
talk2dino.to(device)
# Load CLIP model
clip_model, clip_preprocess = clip.load("ViT-B/16", device=device, jit=False)
tokenizer = clip.tokenize
# Example: Tokenize and project text features
texts = ["a cat"]
text_tokens = tokenizer(texts).to(device)
text_features = clip_model.encode_text(text_tokens)
projected_text_features = talk2dino.project_clip_txt(text_features)
Demo
In demo.py we provide a simple example on how to use Talk2DINO for inference on a given image with custom textual categories. Run
python demo.py --input custom_input_image --output custom_output_seg [--with_background] --textual_categories category_1,category_2,..
Example:
python demo.py --input assets/pikachu.png --output pikachu_seg.png --textual_categories pikachu,traffic_sign,forest,route
Result:

| 
|
Installation
# Create a new environment with Python 3.10
conda create --name talk2dino python=3.10 -c conda-forge
conda activate talk2dino
# Install compilers for C++/CUDA extensions
conda install -c conda-forge "gxx_linux-64=11.*" "gcc_linux-64=11.*"
# Install CUDA toolkit and cuDNN
conda install -c nvidia/label/cuda-11.7.0 cuda
conda install -c nvidia/label/cuda-11.7.0 cuda-nvcc
conda install -c conda-forge cudnn cudatoolkit=11.7.0
# Install PyTorch 2.1 with CUDA 11.8 support
# Note: This is crucial, as it matches the requirements of mmcv-full 1.7.2
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
# Install other dependencies
pip install -r requirements.txt
pip install -U openmim
mim install mmengine
# Install a compatible version of mmcv-full (1.7.2) for PyTorch 2.1
pip install mmcv-full==1.7.2 -f https://download.openmmlab.com/mmcv/dist/cu118/torch2.1.0/index.html
# Install mmsegmentation
pip install mmsegmentation==0.30.0
Qualitative Results
| Image | Ground Truth | FreeDA | ProxyCLIP | CLIP-DINOiser | Ours (Talk2DINO) |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Reference
If you found this code useful, please cite the following paper:
@misc{barsellotti2024talkingdinobridgingselfsupervised,
title={Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation},
author={Luca Barsellotti and Lorenzo Bianchi and Nicola Messina and Fabio Carrara and Marcella Cornia and Lorenzo Baraldi and Fabrizio Falchi and Rita Cucchiara},
year={2024},
eprint={2411.19331},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.19331},
}
- Downloads last month
- 39