
modelId
stringlengths 5
138
| author
stringlengths 2
42
| last_modified
unknowndate 2020-02-15 11:33:14
2025-05-07 12:31:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 449
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
unknowndate 2022-03-02 23:29:04
2025-05-07 12:29:37
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
procit008/vits_dutch_female_v0.2 | procit008 | "2025-05-05T21:18:52Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"vits",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T21:18:38Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF | mradermacher | "2025-05-05T21:18:05Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"grpo,",
"biomed,reasoning",
"en",
"dataset:openlifescienceai/medmcqa",
"base_model:rgb2gbr/GRPO_BioMedmcqa_Qwen2.5-0.5B",
"base_model:quantized:rgb2gbr/GRPO_BioMedmcqa_Qwen2.5-0.5B",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | "2025-05-05T21:10:18Z" | ---
base_model: rgb2gbr/GRPO_BioMedmcqa_Qwen2.5-0.5B
datasets:
- openlifescienceai/medmcqa
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
tags:
- grpo,
- biomed,reasoning
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/rgb2gbr/GRPO_BioMedmcqa_Qwen2.5-0.5B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ1_S.gguf) | i1-IQ1_S | 0.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ1_M.gguf) | i1-IQ1_M | 0.4 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ2_S.gguf) | i1-IQ2_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ2_M.gguf) | i1-IQ2_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.4 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ3_S.gguf) | i1-IQ3_S | 0.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q2_K.gguf) | i1-Q2_K | 0.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ3_M.gguf) | i1-IQ3_M | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 0.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q4_0.gguf) | i1-Q4_0 | 0.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.5 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.5 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q4_1.gguf) | i1-Q4_1 | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.5 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/GRPO_BioMedmcqa_Qwen2.5-0.5B-i1-GGUF/resolve/main/GRPO_BioMedmcqa_Qwen2.5-0.5B.i1-Q6_K.gguf) | i1-Q6_K | 0.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
NMolby/profile-pictures | NMolby | "2025-05-05T21:05:21Z" | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-05-05T20:41:02Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: nico
---
# Profile Pictures
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `nico` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "nico",
"lora_weights": "https://huggingface.co/NMolby/profile-pictures/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('NMolby/profile-pictures', weight_name='lora.safetensors')
image = pipeline('nico').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/NMolby/profile-pictures/discussions) to add images that show off what you’ve made with this LoRA.
|
kessinger/dominic | kessinger | "2025-05-05T20:58:02Z" | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T20:58:02Z" | ---
license: apache-2.0
---
|
rudrashah/RLM_hingu | rudrashah | "2025-05-05T20:45:42Z" | 0 | 2 | keras-hub | [
"keras-hub",
"hinglish",
"text-generation",
"hi",
"en",
"dataset:Abhishekcr448/Hinglish-Everyday-Conversations-1M",
"base_model:google/gemma-3-1b-it",
"base_model:finetune:google/gemma-3-1b-it",
"license:mit",
"region:us"
] | text-generation | "2025-05-05T15:32:04Z" | ---
license: mit
datasets:
- Abhishekcr448/Hinglish-Everyday-Conversations-1M
language:
- hi
- en
base_model:
- google/gemma-3-1b-it
pipeline_tag: text-generation
tags:
- hinglish
library_name: keras-hub
---
# RLM_hingu
<p align="center">
<a href="https://www.buymeacoffee.com/rudrashah" target="_blank">
<img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;">
</a>
</p>
**RLM_hingu** is a fine-tuned version of the [Gemma-3B Instruct](https://huggingface.co/google/gemma-1.1-1b-it) model, adapted for casual Hinglish (Hindi-English) conversation using the `keras-nlp` framework. It is designed for lightweight conversational tasks in Hinglish, optimized with the `JAX` backend for efficiency.
## Model Overview
- **Base model**: `gemma3_instruct_1b`
- **Library**: [`keras-nlp`](https://github.com/keras-team/keras-nlp)
- **Backend**: JAX (recommended for best performance)
- **Sampling Method**: Top-K (k=10)
- **Use Case**: Conversational Hinglish response generation
## Usage
``` python
from keras_nlp.models import Gemma3CausalLM
from keras_nlp.samplers import TopKSampler
model = Gemma3CausalLM.from_preset("hf://rudrashah/RLM_hingu")
template = "Question:\n{question}\n\nAnswer:\n{answer}"
prompt = template.format(
question="Rudra acha ladka hai?",
answer="",
)
output = model.generate(prompt, max_length=256)
print(output)
```
```output
Question:
Rudra acha ladka hai?
Answer:
haan, sabse best hai.
```
To run RLM_hingu, just paste this code and wait. |
silviasapora/gemma-7b-sft-shuffled-dpo-shuffled-5e-7-005-v140 | silviasapora | "2025-05-05T20:39:34Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T20:17:05Z" | ---
library_name: transformers
model_name: gemma-7b-sft-shuffled-dpo-shuffled-5e-7-005-v140
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for gemma-7b-sft-shuffled-dpo-shuffled-5e-7-005-v140
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="silviasapora/gemma-7b-sft-shuffled-dpo-shuffled-5e-7-005-v140", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/silvias/huggingface/runs/7fsvu452)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.2.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
li-muyang/zephyr-7b-sft-full | li-muyang | "2025-05-05T20:28:02Z" | 11 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:generator",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-01-04T10:52:36Z" | ---
library_name: transformers
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
datasets:
- generator
model-index:
- name: zephyr-7b-sft-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-sft-full
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9286
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.977 | 0.0923 | 100 | 0.9750 |
| 0.9604 | 0.1846 | 200 | 0.9686 |
| 0.961 | 0.2769 | 300 | 0.9619 |
| 0.9426 | 0.3692 | 400 | 0.9555 |
| 0.9585 | 0.4615 | 500 | 0.9498 |
| 0.9288 | 0.5538 | 600 | 0.9442 |
| 0.9138 | 0.6461 | 700 | 0.9394 |
| 0.9061 | 0.7383 | 800 | 0.9351 |
| 0.9229 | 0.8306 | 900 | 0.9314 |
| 0.9099 | 0.9229 | 1000 | 0.9286 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.5.1+rocm6.2
- Datasets 3.5.0
- Tokenizers 0.20.3
|
chargoddard/mergekit-slerp-qdwxicz | chargoddard | "2025-05-05T20:24:22Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:arcee-ai/sec-mistral-7b-instruct-1.6-epoch",
"base_model:merge:arcee-ai/sec-mistral-7b-instruct-1.6-epoch",
"base_model:cognitivecomputations/dolphin-2.8-mistral-7b-v02",
"base_model:merge:cognitivecomputations/dolphin-2.8-mistral-7b-v02",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T20:19:50Z" | ---
base_model:
- cognitivecomputations/dolphin-2.8-mistral-7b-v02
- arcee-ai/sec-mistral-7b-instruct-1.6-epoch
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [SLERP](https://en.wikipedia.org/wiki/Slerp) merge method.
### Models Merged
The following models were included in the merge:
* [cognitivecomputations/dolphin-2.8-mistral-7b-v02](https://huggingface.co/cognitivecomputations/dolphin-2.8-mistral-7b-v02)
* [arcee-ai/sec-mistral-7b-instruct-1.6-epoch](https://huggingface.co/arcee-ai/sec-mistral-7b-instruct-1.6-epoch)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: arcee-ai/sec-mistral-7b-instruct-1.6-epoch
layer_range: [0, 32]
- model: cognitivecomputations/dolphin-2.8-mistral-7b-v02
layer_range: [0, 32]
merge_method: slerp
base_model: cognitivecomputations/dolphin-2.8-mistral-7b-v02
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
adamsdossantos/huggy | adamsdossantos | "2025-05-05T20:21:16Z" | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | "2025-05-05T20:21:10Z" | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: adamsdossantos/huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
art0123/ComfyUI_art | art0123 | "2025-05-05T20:09:35Z" | 0 | 19 | null | [
"region:us"
] | null | "2024-09-05T05:20:23Z" | ComfyUI_art_v3 (Сборка) - Обновление! 🔧
✨Изменения:
ComfyUI и все узлы приведены к актуальным версиям по состоянию на 05.05.2025.
Обновлен Pytorch до версии 2.7.0 + cuda128.
Обновлен Xformers до версии 0.0.31.dev1030.
✨ Добавлены новые узлы. Полный список...
AGSoft, cg-use-everywhere, ComfyUI_AdvancedRefluxControl, ComfyUI_bnb_nf4_fp4_Loaders, ComfyUI_Comfyroll_CustomNodes, comfyui_controlnet_aux, comfyui_custom_nodes_alekpet, comfyui_essentials, comfyui_faceanalysis, comfyui_instantid, comfyui_ipadapter_plus, comfyui_layerstyle, ComfyUI_LayerStyle_Advance, comfyui_patches_ll, comfyui_pulid_flux_ll, comfyui_segment_anything, comfyui_ttp_toolset, comfyui_ultimatesdupscale, comfyui_zenid, comfyui-art-venture, ComfyUI-AutoCropFaces, ComfyUI-Crystools, comfyui-custom-scripts, comfyui-detail-daemon, comfyui-enricos-nodes, comfyui-florence2, ComfyUI-Fluxtapoz, ComfyUI-FramePackWrapper, ComfyUI-GGUF, comfyui-ic-light, comfyui-impact-pack, comfyui-impact-subpack, comfyui-inpaint-cropandstitch, comfyui-inpaint-nodes, comfyui-inspire-pack, comfyui-kjnodes, comfyui-manager, comfyui-mxtoolkit, ComfyUI-PuLID-Flux-Enhanced, comfyui-reactor-node, comfyui-rmbg, ComfyUI-segment-anything-2, Comfyui-StableSR, comfyui-supir, ComfyUI-TiledDiffusion, comfyui-videohelpersuite, comfyui-wd14-tagger, efficiency-nodes-comfyui, facerestore_cf, pulid_comfyui, rgthree-comfy, teacache, was-node-suite-comfyui, wavespeed
//.........................................................................................
ComfyUI_art_v2 (Сборка)
Что нового:
ComfyUI и все текущие узлы приведены к актуальным версиям по состоянию на 08.02.2025.
Обновлен Pytorch до версии 2.6.0 + cuda126
Обновлен Xformers до версии 0.0.29.post2
Добавлены новые узлы:
Comfy-WaveSpeed, ComfyUI-TeaCache, ComfyUI_Patches_ll, ComfyUI-SUPIR, comfyui_ttp_toolset, comfyui-detail-daemon, comfyui_zenid
//.........................................................................................
ComfyUI_art_v1 (Сборка)
Приветствую всех, кто любит экспериментировать с нейросетями и создавать уникальные арты! Сегодня я хочу представить вам свою сборку ComfyUI, которая станет вашим надежным помощником в мире цифрового творчества.
Что внутри?
В сборку интегрированы стабильные версии ключевых компонентов: Pytorch, Xformers, Insightface, Onnxruntime, Facexlib, Dlib и Bitsandbytes. Также добавлены все необходимые модели для работы с Реактором.
Для вашего удобства в сборку включены полезные пакеты нод, которые значительно расширяют возможности ComfyUI:
ComfyUI-Manager, Comfyui-Crystools, Rgthree-Comfy, ComfyUI-Custom-Scripts, Comfyui-Kjnodes, ComfyUI Impact Pack, ComfyUI Impact Subpack, ComfyUI Inspire Pack, Cg-use-everywhere, ComfyUI-Easy-Use, Comfyroll_CustomNodes, ComfyUI_Custom_Nodes_AlekPet, Comfyui-Reactor-node, ComfyUI-GGUF, Comfyui_bnb_nf4_loaders, ComfyUI_IPAdapter_plus, ComfyUI_InstantID, ComfyUI_essentials, ComfyUI_FaceAnalysis, PuLID_ComfyUI, ComfyUI_PuLID_Flux_ll, ComfyUI-Florence2, ComfyUI-AutoCropFaces, Comfyui_controlnet_aux, ComfyUI_AdvancedRefluxControl, ComfyUI_UltimateSDUpscale, Comfyui-inpaint-nodes, ComfyUI-Inpaint-CropAndStitch, ComfyUI-Fluxtapoz, ComfyUI-mxToolkit, ComfyUI-RMBG, ComfyUI ArtVenture, ComfyUI-enricos-nodes, ComfyUI-TiledDiffusion.
Как установить?
1. Просто распакуйте архив.
2. Для запуска используйте run_nvidia_gpu.bat.
Как обновить.
1. Перейдите в папку Install.
2. Запустите батник update_ComfyUI.bat, чтобы обновить ComfyUI до актуальной версии.
В папке Install также найдете дополнительные батники для выборочной установки компонентов или переустановки сломанных элементов. Если вы используете другую сборку ComfyUI, просто скопируйте папку Install в корень вашей ComfyUI, и пользуйтесь на здоровье!
В заключение
Эта сборка создана специально для тех, кто только начинает свой путь в мире нейросетей и цифрового искусства. Я постарался сделать всё возможное, чтобы ваше знакомство с ComfyUI было максимально простым и комфортным. Всё, что вам нужно, уже интегрировано и настроено – просто распакуйте архив, следуйте инструкциям, и вы сможете сразу приступить к созданию своих первых шедевров.
Надеюсь, что ComfyUI станет вашим надежным помощником, вдохновит на эксперименты и поможет раскрыть ваш творческий потенциал. Не бойтесь пробовать новое, задавать вопросы и делиться своими результатами! Удачи в творчестве, и пусть ваши идеи оживают с помощью этой сборки! 🎨✨ |
MohamedAhmedAE/Llama-3.2-3B-Instruct-Medical-Finetune-v3 | MohamedAhmedAE | "2025-05-05T20:03:58Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-04-20T22:48:01Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mlfoundations-dev/d1_code_fasttext_3k | mlfoundations-dev | "2025-05-05T20:03:13Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T12:14:15Z" | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: d1_code_fasttext_3k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# d1_code_fasttext_3k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/d1_code_fasttext_3k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
mluger/vitFaceExpressionBalancedFocalLoss | mluger | "2025-05-05T19:56:52Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2025-04-23T14:12:20Z" | ---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vitFaceExpressionBalancedFocalLoss
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vitFaceExpressionBalancedFocalLoss
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2569
- Accuracy: 0.6952
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4251 | 1.0 | 898 | 0.3174 | 0.6183 |
| 0.2667 | 2.0 | 1796 | 0.2676 | 0.6573 |
| 0.205 | 3.0 | 2694 | 0.2580 | 0.6776 |
| 0.1659 | 4.0 | 3592 | 0.2674 | 0.6826 |
| 0.1374 | 5.0 | 4490 | 0.2647 | 0.6885 |
| 0.1068 | 6.0 | 5388 | 0.2573 | 0.6935 |
| 0.0881 | 7.0 | 6286 | 0.2581 | 0.6982 |
| 0.0832 | 8.0 | 7184 | 0.2569 | 0.6952 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
YassineeM/tiktok | YassineeM | "2025-05-05T19:49:12Z" | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T19:49:12Z" | ---
license: apache-2.0
---
|
Theleebebe/my-zoom-fb-validation-model | Theleebebe | "2025-05-05T19:44:07Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-05-05T19:43:33Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
alelisita/reic | alelisita | "2025-05-05T19:28:14Z" | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-05-05T19:16:26Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Reic
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/alelisita/reic/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('alelisita/reic', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/alelisita/reic/discussions) to add images that show off what you’ve made with this LoRA.
|
MinaMila/Phi3_unlearned_0.5_0.25_0.5 | MinaMila | "2025-05-05T19:19:54Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T19:16:44Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
xbilek25/whisper-medium-en-cv-8.0 | xbilek25 | "2025-05-05T19:14:09Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"en",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:openai/whisper-medium.en",
"base_model:finetune:openai/whisper-medium.en",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2025-05-05T17:25:46Z" | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: openai/whisper-medium.en
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-medium-en-cv-8.0
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 17.0
type: mozilla-foundation/common_voice_17_0
args: 'config: en, split: test'
metrics:
- name: Wer
type: wer
value: 22.90263319044703
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium-en-cv-8.0
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the Common Voice 17.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7352
- Wer: 22.9026
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 48
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 375
- training_steps: 2250
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| No log | 0 | 0 | 2.0556 | 32.3025 |
| 0.5507 | 0.1667 | 375 | 0.7920 | 25.9032 |
| 0.3861 | 0.3333 | 750 | 0.7215 | 24.6479 |
| 0.205 | 1.1667 | 1125 | 0.7130 | 22.8108 |
| 0.1431 | 1.3333 | 1500 | 0.7193 | 23.8212 |
| 0.0802 | 2.1667 | 1875 | 0.7302 | 23.5150 |
| 0.0626 | 2.3333 | 2250 | 0.7352 | 22.9026 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
Liyusan-sondra/Full.liyumisa.emo.video.viral.la.nina.emo.video.liyusan.sondra.video.viral | Liyusan-sondra | "2025-05-05T19:11:04Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T19:10:35Z" | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=Liyusan-sondra)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=Liyusan-sondra)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=Liyusan-sondra) |
vivnatan/legal-ft-20c85cc6-30d1-49ca-97e6-cce1045a4b4a | vivnatan | "2025-05-05T19:09:43Z" | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:780",
"loss:MatryoshkaLoss",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:2205.13147",
"arxiv:1705.00652",
"base_model:Snowflake/snowflake-arctic-embed-l",
"base_model:finetune:Snowflake/snowflake-arctic-embed-l",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2025-05-05T19:08:28Z" | ---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:780
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
base_model: Snowflake/snowflake-arctic-embed-l
widget:
- source_sentence: What is one potential negative use of LLMs related to education?
sentences:
- 'A year ago, the only organization that had released a generally useful LLM was
OpenAI. We’ve now seen better-than-GPT-3 class models produced by Anthropic, Mistral,
Google, Meta, EleutherAI, Stability AI, TII in Abu Dhabi (Falcon), Microsoft Research,
xAI, Replit, Baidu and a bunch of other organizations.
The training cost (hardware and electricity) is still significant—initially millions
of dollars, but that seems to have dropped to the tens of thousands already. Microsoft’s
Phi-2 claims to have used “14 days on 96 A100 GPUs”, which works out at around
$35,000 using current Lambda pricing.'
- 'Then in December, the Chatbot Arena team introduced a whole new leaderboard for
this feature, driven by users building the same interactive app twice with two
different models and voting on the answer. Hard to come up with a more convincing
argument that this feature is now a commodity that can be effectively implemented
against all of the leading models.
I’ve been tinkering with a version of this myself for my Datasette project, with
the goal of letting users use prompts to build and iterate on custom widgets and
data visualizations against their own data. I also figured out a similar pattern
for writing one-shot Python programs, enabled by uv.'
- 'Here’s the sequel to this post: Things we learned about LLMs in 2024.
Large Language Models
In the past 24-36 months, our species has discovered that you can take a GIANT
corpus of text, run it through a pile of GPUs, and use it to create a fascinating
new kind of software.
LLMs can do a lot of things. They can answer questions, summarize documents, translate
from one language to another, extract information and even write surprisingly
competent code.
They can also help you cheat at your homework, generate unlimited streams of fake
content and be used for all manner of nefarious purposes.'
- source_sentence: What is the significance of the UK’s Railway Mania in the context
of railway construction?
sentences:
- 'An interesting point of comparison here could be the way railways rolled out
around the world in the 1800s. Constructing these required enormous investments
and had a massive environmental impact, and many of the lines that were built
turned out to be unnecessary—sometimes multiple lines from different companies
serving the exact same routes!
The resulting bubbles contributed to several financial crashes, see Wikipedia
for Panic of 1873, Panic of 1893, Panic of 1901 and the UK’s Railway Mania. They
left us with a lot of useful infrastructure and a great deal of bankruptcies and
environmental damage.
The year of slop'
- 'The top five: ai (342), generativeai (300), llms (287), openai (86), chatgpt
(78).
I’ve written a lot about this stuff!
I grabbed a screenshot of my Plausible analytics for the year, fed that to ChatGPT
Vision, told it to extract the data into a table, then got it to mix in entry
titles (from a SQL query it wrote) and produced this table with it. Here are my
top entries this year by amount of traffic:
Article
Visitors
Pageviews
Bing: “I will not harm you unless you harm me first”
1.1M
1.3M
Leaked Google document: “We Have No Moat, And Neither Does OpenAI”
132k
162k
Large language models are having their Stable Diffusion moment
121k
150k
Prompt injection: What’s the worst that can happen?
79.8k
95.9k'
- 'Law is not ethics. Is it OK to train models on people’s content without their
permission, when those models will then be used in ways that compete with those
people?
As the quality of results produced by AI models has increased over the year, these
questions have become even more pressing.
The impact on human society in terms of these models is already huge, if difficult
to objectively measure.
People have certainly lost work to them—anecdotally, I’ve seen this for copywriters,
artists and translators.
There are a great deal of untold stories here. I’m hoping 2024 sees significant
amounts of dedicated journalism on this topic.
My blog in 2023
Here’s a tag cloud for content I posted to my blog in 2023 (generated using Django
SQL Dashboard):'
- source_sentence: Can you build an LLM without the right data? Why or why not?
sentences:
- 'Intuitively, one would expect that systems this powerful would take millions
of lines of complex code. Instead, it turns out a few hundred lines of Python
is genuinely enough to train a basic version!
What matters most is the training data. You need a lot of data to make these
things work, and the quantity and quality of the training data appears to be the
most important factor in how good the resulting model is.
If you can gather the right data, and afford to pay for the GPUs to train it,
you can build an LLM.'
- 'Embeddings: What they are and why they matter
61.7k
79.3k
Catching up on the weird world of LLMs
61.6k
85.9k
llamafile is the new best way to run an LLM on your own computer
52k
66k
Prompt injection explained, with video, slides, and a transcript
51k
61.9k
AI-enhanced development makes me more ambitious with my projects
49.6k
60.1k
Understanding GPT tokenizers
49.5k
61.1k
Exploring GPTs: ChatGPT in a trench coat?
46.4k
58.5k
Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
40.5k
49.2k
How to implement Q&A against your documentation with GPT3, embeddings and Datasette
37.3k
44.9k
Lawyer cites fake cases invented by ChatGPT, judge is not amused
37.1k
47.4k'
- 'One way to think about these models is an extension of the chain-of-thought prompting
trick, first explored in the May 2022 paper Large Language Models are Zero-Shot
Reasoners.
This is that trick where, if you get a model to talk out loud about a problem
it’s solving, you often get a result which the model would not have achieved otherwise.
o1 takes this process and further bakes it into the model itself. The details
are somewhat obfuscated: o1 models spend “reasoning tokens” thinking through the
problem that are not directly visible to the user (though the ChatGPT UI shows
a summary of them), then outputs a final result.'
- source_sentence: What was the estimated training cost for DeepSeek v3?
sentences:
- 'Now that those features are rolling out they’re pretty weak. As an LLM power-user
I know what these models are capable of, and Apple’s LLM features offer a pale
imitation of what a frontier LLM can do. Instead we’re getting notification summaries
that misrepresent news headlines and writing assistant tools that I’ve not found
useful at all. Genmoji are kind of fun though.
The rise of inference-scaling “reasoning” models
The most interesting development in the final quarter of 2024 was the introduction
of a new shape of LLM, exemplified by OpenAI’s o1 models—initially released as
o1-preview and o1-mini on September 12th.'
- 'Prompt injection is a natural consequence of this gulibility. I’ve seen precious
little progress on tackling that problem in 2024, and we’ve been talking about
it since September 2022.
I’m beginning to see the most popular idea of “agents” as dependent on AGI itself.
A model that’s robust against gulliblity is a very tall order indeed.
Evals really matter
Anthropic’s Amanda Askell (responsible for much of the work behind Claude’s Character):'
- 'DeepSeek v3 is a huge 685B parameter model—one of the largest openly licensed
models currently available, significantly bigger than the largest of Meta’s Llama
series, Llama 3.1 405B.
Benchmarks put it up there with Claude 3.5 Sonnet. Vibe benchmarks (aka the Chatbot
Arena) currently rank it 7th, just behind the Gemini 2.0 and OpenAI 4o/o1 models.
This is by far the highest ranking openly licensed model.
The really impressive thing about DeepSeek v3 is the training cost. The model
was trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. Llama
3.1 405B trained 30,840,000 GPU hours—11x that used by DeepSeek v3, for a model
that benchmarks slightly worse.'
- source_sentence: How does the author describe the clarity of the term "agents"?
sentences:
- 'OpenAI made GPT-4o free for all users in May, and Claude 3.5 Sonnet was freely
available from its launch in June. This was a momentus change, because for the
previous year free users had mostly been restricted to GPT-3.5 level models, meaning
new users got a very inaccurate mental model of what a capable LLM could actually
do.
That era appears to have ended, likely permanently, with OpenAI’s launch of ChatGPT
Pro. This $200/month subscription service is the only way to access their most
capable model, o1 Pro.
Since the trick behind the o1 series (and the future models it will undoubtedly
inspire) is to expend more compute time to get better results, I don’t think those
days of free access to the best available models are likely to return.'
- 'Things we learned about LLMs in 2024
Simon Willison’s Weblog
Subscribe
Things we learned about LLMs in 2024
31st December 2024
A lot has happened in the world of Large Language Models over the course of 2024.
Here’s a review of things we figured out about the field in the past twelve months,
plus my attempt at identifying key themes and pivotal moments.
This is a sequel to my review of 2023.
In this article:'
- '“Agents” still haven’t really happened yet
I find the term “agents” extremely frustrating. It lacks a single, clear and widely
understood meaning... but the people who use the term never seem to acknowledge
that.
If you tell me that you are building “agents”, you’ve conveyed almost no information
to me at all. Without reading your mind I have no way of telling which of the
dozens of possible definitions you are talking about.'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: SentenceTransformer based on Snowflake/snowflake-arctic-embed-l
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Unknown
type: unknown
metrics:
- type: cosine_accuracy@1
value: 0.8416666666666667
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.975
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9916666666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 1.0
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.8416666666666667
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.32499999999999996
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.19833333333333336
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.10000000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.8416666666666667
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.975
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9916666666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 1.0
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.933195287437209
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9105555555555555
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9105555555555557
name: Cosine Map@100
---
# SentenceTransformer based on Snowflake/snowflake-arctic-embed-l
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [Snowflake/snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l). It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [Snowflake/snowflake-arctic-embed-l](https://huggingface.co/Snowflake/snowflake-arctic-embed-l) <!-- at revision d8fb21ca8d905d2832ee8b96c894d3298964346b -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 1024 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("vivnatan/legal-ft-20c85cc6-30d1-49ca-97e6-cce1045a4b4a")
# Run inference
sentences = [
'How does the author describe the clarity of the term "agents"?',
'“Agents” still haven’t really happened yet\nI find the term “agents” extremely frustrating. It lacks a single, clear and widely understood meaning... but the people who use the term never seem to acknowledge that.\nIf you tell me that you are building “agents”, you’ve conveyed almost no information to me at all. Without reading your mind I have no way of telling which of the dozens of possible definitions you are talking about.',
'OpenAI made GPT-4o free for all users in May, and Claude 3.5 Sonnet was freely available from its launch in June. This was a momentus change, because for the previous year free users had mostly been restricted to GPT-3.5 level models, meaning new users got a very inaccurate mental model of what a capable LLM could actually do.\nThat era appears to have ended, likely permanently, with OpenAI’s launch of ChatGPT Pro. This $200/month subscription service is the only way to access their most capable model, o1 Pro.\nSince the trick behind the o1 series (and the future models it will undoubtedly inspire) is to expend more compute time to get better results, I don’t think those days of free access to the best available models are likely to return.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.8417 |
| cosine_accuracy@3 | 0.975 |
| cosine_accuracy@5 | 0.9917 |
| cosine_accuracy@10 | 1.0 |
| cosine_precision@1 | 0.8417 |
| cosine_precision@3 | 0.325 |
| cosine_precision@5 | 0.1983 |
| cosine_precision@10 | 0.1 |
| cosine_recall@1 | 0.8417 |
| cosine_recall@3 | 0.975 |
| cosine_recall@5 | 0.9917 |
| cosine_recall@10 | 1.0 |
| **cosine_ndcg@10** | **0.9332** |
| cosine_mrr@10 | 0.9106 |
| cosine_map@100 | 0.9106 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 780 training samples
* Columns: <code>sentence_0</code> and <code>sentence_1</code>
* Approximate statistics based on the first 780 samples:
| | sentence_0 | sentence_1 |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 17.51 tokens</li><li>max: 34 tokens</li></ul> | <ul><li>min: 43 tokens</li><li>mean: 135.32 tokens</li><li>max: 214 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 |
|:-----------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>What is the main discovery about Large Language Models (LLMs) in the past 24-36 months?</code> | <code>Here’s the sequel to this post: Things we learned about LLMs in 2024.<br>Large Language Models<br>In the past 24-36 months, our species has discovered that you can take a GIANT corpus of text, run it through a pile of GPUs, and use it to create a fascinating new kind of software.<br>LLMs can do a lot of things. They can answer questions, summarize documents, translate from one language to another, extract information and even write surprisingly competent code.<br>They can also help you cheat at your homework, generate unlimited streams of fake content and be used for all manner of nefarious purposes.</code> |
| <code>What resources are used to create Large Language Models?</code> | <code>Here’s the sequel to this post: Things we learned about LLMs in 2024.<br>Large Language Models<br>In the past 24-36 months, our species has discovered that you can take a GIANT corpus of text, run it through a pile of GPUs, and use it to create a fascinating new kind of software.<br>LLMs can do a lot of things. They can answer questions, summarize documents, translate from one language to another, extract information and even write surprisingly competent code.<br>They can also help you cheat at your homework, generate unlimited streams of fake content and be used for all manner of nefarious purposes.</code> |
| <code>What are some of the capabilities of LLMs mentioned in the context?</code> | <code>Here’s the sequel to this post: Things we learned about LLMs in 2024.<br>Large Language Models<br>In the past 24-36 months, our species has discovered that you can take a GIANT corpus of text, run it through a pile of GPUs, and use it to create a fascinating new kind of software.<br>LLMs can do a lot of things. They can answer questions, summarize documents, translate from one language to another, extract information and even write surprisingly competent code.<br>They can also help you cheat at your homework, generate unlimited streams of fake content and be used for all manner of nefarious purposes.</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 10
- `per_device_eval_batch_size`: 10
- `num_train_epochs`: 10
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 10
- `per_device_eval_batch_size`: 10
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 10
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | Training Loss | cosine_ndcg@10 |
|:------:|:----:|:-------------:|:--------------:|
| 0.6410 | 50 | - | 0.9199 |
| 1.0 | 78 | - | 0.9322 |
| 1.2821 | 100 | - | 0.9351 |
| 1.9231 | 150 | - | 0.9415 |
| 2.0 | 156 | - | 0.9434 |
| 2.5641 | 200 | - | 0.9438 |
| 3.0 | 234 | - | 0.9404 |
| 3.2051 | 250 | - | 0.9432 |
| 3.8462 | 300 | - | 0.9345 |
| 4.0 | 312 | - | 0.9356 |
| 4.4872 | 350 | - | 0.9393 |
| 5.0 | 390 | - | 0.9358 |
| 5.1282 | 400 | - | 0.9316 |
| 5.7692 | 450 | - | 0.9335 |
| 6.0 | 468 | - | 0.9350 |
| 6.4103 | 500 | 1.3465 | 0.9412 |
| 7.0 | 546 | - | 0.9375 |
| 7.0513 | 550 | - | 0.9406 |
| 7.6923 | 600 | - | 0.9410 |
| 8.0 | 624 | - | 0.9375 |
| 8.3333 | 650 | - | 0.9333 |
| 8.9744 | 700 | - | 0.9375 |
| 9.0 | 702 | - | 0.9375 |
| 9.6154 | 750 | - | 0.9332 |
| 10.0 | 780 | - | 0.9332 |
### Framework Versions
- Python: 3.11.12
- Sentence Transformers: 4.1.0
- Transformers: 4.51.3
- PyTorch: 2.6.0+cu124
- Accelerate: 1.6.0
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
Jobz-Hunting-Sajal-Malik-l/wATCH.Jobz.Hunting.Sajal.Malik.viral.video.original.X-New | Jobz-Hunting-Sajal-Malik-l | "2025-05-05T19:08:57Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T19:02:28Z" | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?Jobz-Hunting)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?Jobz-Hunting)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?Jobz-Hunting) |
MrRobotoAI/A6 | MrRobotoAI | "2025-05-05T18:48:39Z" | 34 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2212.04089",
"base_model:MrRobotoAI/A4",
"base_model:merge:MrRobotoAI/A4",
"base_model:MrRobotoAI/A5",
"base_model:merge:MrRobotoAI/A5",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T06:19:57Z" | ---
base_model:
- MrRobotoAI/A5
- MrRobotoAI/A4
library_name: transformers
tags:
- mergekit
- merge
---
# merge 13,500
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Task Arithmetic](https://arxiv.org/abs/2212.04089) merge method using [MrRobotoAI/A5](https://huggingface.co/MrRobotoAI/A5) as a base.
### Models Merged
The following models were included in the merge:
* [MrRobotoAI/A4](https://huggingface.co/MrRobotoAI/A4)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: task_arithmetic
models:
- model: MrRobotoAI/A5
parameters:
weight:
- filter: v_proj
value: [0.8, 0.8, 0.6, 0.7, 0.8, 0.8, 0.8, 0.7, 0.6, 0.8, 0.8]
- filter: o_proj
value: [0.8, 0.8, 0.6, 0.7, 0.8, 0.8, 0.8, 0.7, 0.6, 0.8, 0.8]
- filter: up_proj
value: [0.8, 0.8, 0.6, 0.7, 0.8, 0.8, 0.8, 0.7, 0.6, 0.8, 0.8]
- filter: gate_proj
value: [0.8, 0.8, 0.6, 0.7, 0.8, 0.8, 0.8, 0.7, 0.6, 0.8, 0.8]
- filter: down_proj
value: [0.8, 0.8, 0.6, 0.7, 0.8, 0.8, 0.8, 0.7, 0.6, 0.8, 0.8]
- value: 1
- model: MrRobotoAI/A4
parameters:
weight:
- filter: v_proj
value: [0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.2, 0.3, 0.4, 0.2, 0.2]
- filter: o_proj
value: [0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.2, 0.3, 0.4, 0.2, 0.2]
- filter: up_proj
value: [0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.2, 0.3, 0.4, 0.2, 0.2]
- filter: gate_proj
value: [0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.2, 0.3, 0.4, 0.2, 0.2]
- filter: down_proj
value: [0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.2, 0.3, 0.4, 0.2, 0.2]
- value: 0
base_model: MrRobotoAI/A5
dtype: bfloat16
```
|
A7medsala7/my_awesome_model | A7medsala7 | "2025-05-05T18:39:39Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-05-05T17:46:14Z" | ---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2370
- Accuracy: 0.9311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2218 | 1.0 | 1563 | 0.1980 | 0.9254 |
| 0.1431 | 2.0 | 3126 | 0.2370 | 0.9311 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
Venkat423/Gemma-3-4b-finetuned-final | Venkat423 | "2025-05-05T18:13:02Z" | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | "2025-05-05T10:18:32Z" |
---
language: bn
license: cc-by-nc-4.0
datasets:
- https://www.kaggle.com/datasets/saurabhshahane/bangla-wikipedia
- https://github.com/shuhanmirza/Bengali-Poem-Dataset
---
# Gemma-3-4b Fine-tuned on Bengali Wikipedia and poem dataset
|
odedovadia/Qwen3-4B-chess-10K-single-move-sft-2025-05-05-red-1K-no-cot-checkpoint-240 | odedovadia | "2025-05-05T17:36:34Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T17:34:27Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
scb10x/typhoon2.1-gemma3-4b | scb10x | "2025-05-05T17:31:32Z" | 7 | 0 | null | [
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:2412.13702",
"license:gemma",
"region:us"
] | text-generation | "2025-05-01T15:15:27Z" | ---
license: gemma
pipeline_tag: text-generation
---
**Typhoon2.1-Gemma3-4B**: Thai Large Language Model (Instruct)
**Typhoon2.1-Gemma3-4B** is a instruct Thai 🇹🇭 large language model with 4 billion parameters, a 128K context length, and function-calling capabilities. It is based on Gemma3 4B.
Remark: This is text only model. We removed vision encoder for this version due to complexity. Stay-tune for version with vision encoder soon.
## **Performance**
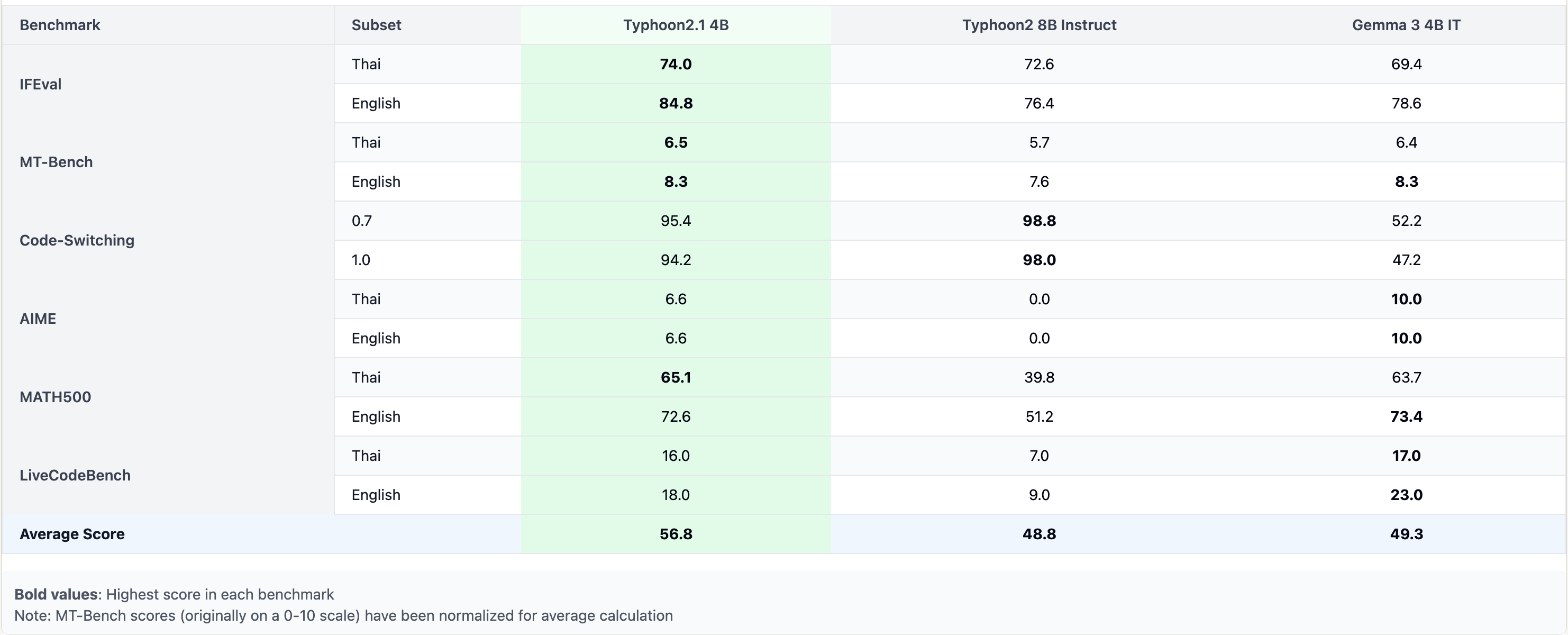
## **Model Description**
- **Model type**: A 4B instruct decoder-only model based on Gemma3 architecture.
- **Requirement**: transformers 4.50.0 or newer.
- **Primary Language(s)**: Thai 🇹🇭 and English 🇬🇧
- **License**: [Gemma License](https://github.com/google-deepmind/gemma/blob/main/LICENSE)
## Usage Example
This code snippet shows how to use the Typhoon2.1-Gemma3-4B model for Thai or English text generation using the transformers library. It includes setting up the model and tokenizer, formatting chat messages in a system-user style, and generating a response.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/typhoon2.1-gemma3-4b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=False # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Deploy as Server
This section shows how to run Typhoon2.1 as an OpenAI-compatible API server using vllm.
```bash
pip install vllm
vllm serve scb10x/typhoon2.1-gemma3-4b --max-model-len 16000 --dtype bfloat16 --tool-call-parser pythonic --enable-auto-tool-choice
# adjust --max-model-len based on your avaliable memory
# you can use --quantization bitsandbytes to reduce the memory use while trade-off inference speed
```
## Using Tools
You can provide tools to the vLLM-powered OpenAI-compatible API for functionality.
```
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco?"}],
tools=tools,
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")
```
## Switching Between Thinking and Non-Thinking Mode
Typhoon supports two modes:
Non-thinking mode (default): Fast response generation without extra reasoning steps.
Thinking mode: The model first reasons internally, then provides a clearer and potentially more accurate final answer.
You can enable thinking mode by:
Setting enable_thinking=True in apply_chat_template.
Using a special system prompt that instructs the model to reason inside <think>...</think> tags.
You can turn on thinking mode by either
- add enable_thinking=True to apply_chat_template
```python
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
```
- manually by supply thinking mode system prompt
```
You are a helpful assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state a response that addresses the user's request and aligns with their preferences, not just providing a direct answer.
```
- in vllm powered openai compatible client you can add chat_template_kwargs to the post payload
```json
{
"model": "scb10x/typhoon2.1-gemma3-4b",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"chat_template_kwargs": {"enable_thinking": true}
}
```
## Budget forcing
This section introduces budget forcing, an advanced technique to let the model spend more time and tokens reasoning before producing a final answer—great for improving performance on complex questions.
```
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
class BudgetForcingHandler:
def __init__(self, model_name: str, max_think_token: int, max_ignore=5, temperature=0.6, seed=32):
self.temperature = temperature
self.seed = seed
self.max_think_token = max_think_token
self.max_ignore = max_ignore
self.model = LLM(model_name, dtype='bfloat16', enforce_eager=True)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.alternative_str = '\nAlternatively'
self.system = """You are a reasoning assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state the final answer."""
def __call__(self, prompts: List[str]):
count_prompt = len(prompts)
prompts = [self.tokenizer.apply_chat_template([{'role': 'system', 'content': self.system}, {'role': 'user', 'content': f'Please solve this math question, and put your final answer within \\boxed{{}}.\n{p}'}], add_generation_prompt=True, tokenize=False) for p in prompts]
sampling_params = SamplingParams(
max_tokens=self.max_think_token,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params
)
outputs = [output.outputs[0].text for output in o]
token_count = [len(output.outputs[0].token_ids) for output in o]
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
for _ in range(self.max_ignore): # Num of times to skip stop token
inference_loop_prompts = []
inference_idx = []
max_inference_token = 0
print('current token count: ', token_count)
for i in range(len(prompts)):
left_budget = self.max_think_token - token_count[i]
if left_budget > 0:
prompts[i] = prompts[i] + self.alternative_str
inference_loop_prompts.append(prompts[i])
inference_idx.append(i)
if left_budget > max_inference_token:
max_inference_token = left_budget
outputs = ['' for _ in range(len(prompts))]
if max_inference_token == 0 or len(inference_loop_prompts) == 0:
break
sampling_params = SamplingParams(
max_tokens=max_inference_token,
min_tokens=1,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
inference_loop_prompts,
sampling_params=sampling_params
)
assert len(inference_idx) == len(inference_loop_prompts)
assert len(inference_idx) == len(o)
for i, output in zip(inference_idx, o):
outputs[i] = output.outputs[0].text
for i, idx in enumerate(inference_idx):
token_count[idx] = token_count[idx] + len(o[i].outputs[0].token_ids)
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
print('generating answer...')
prompts = [p + '\nTime\'s up. End of thinking process. Will answer immediately.\n</think>' for i, p in enumerate(prompts)]
sampling_params = SamplingParams(
max_tokens=2048,
min_tokens=0,
seed=self.seed,
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params,
)
for i in range(len(prompts)):
prompts[i] = prompts[i] + o[i].outputs[0].text
assert len(prompts) == count_prompt
return prompts
handler = BudgetForcingHandler("scb10x/typhoon2.1-gemma3-4b", max_think_token=2048)
handler(["How many r in raspberry?"])
```
## **Intended Uses & Limitations**
This model is an instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
## **Follow us**
**https://twitter.com/opentyphoon**
## **Support**
**https://discord.gg/us5gAYmrxw**
## **Citation**
- If you find Typhoon2 useful for your work, please cite it using:
```
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
``` |
TOMFORD79/Fly79 | TOMFORD79 | "2025-05-05T17:25:09Z" | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | "2025-05-05T17:12:14Z" | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
jahyungu/Llama-3.1-8B-Instruct_ifeval-like-data_random | jahyungu | "2025-05-05T17:02:29Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T13:27:45Z" | ---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B-Instruct
tags:
- generated_from_trainer
model-index:
- name: Llama-3.1-8B-Instruct_ifeval-like-data_random
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.1-8B-Instruct_ifeval-like-data_random
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
mradermacher/MIRAGE-ECE-V2-i1-GGUF | mradermacher | "2025-05-05T17:00:02Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Lil-R/MIRAGE-ECE-V2",
"base_model:quantized:Lil-R/MIRAGE-ECE-V2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | "2025-05-05T12:41:32Z" | ---
base_model: Lil-R/MIRAGE-ECE-V2
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Lil-R/MIRAGE-ECE-V2
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/MIRAGE-ECE-V2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ1_S.gguf) | i1-IQ1_S | 7.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ1_M.gguf) | i1-IQ1_M | 7.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 8.9 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ2_XS.gguf) | i1-IQ2_XS | 9.8 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ2_S.gguf) | i1-IQ2_S | 10.2 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ2_M.gguf) | i1-IQ2_M | 11.0 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.3 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q2_K.gguf) | i1-Q2_K | 12.2 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.5 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.2 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ3_S.gguf) | i1-IQ3_S | 14.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ3_M.gguf) | i1-IQ3_M | 14.6 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 15.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.0 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q4_0.gguf) | i1-Q4_0 | 18.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 19.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q4_1.gguf) | i1-Q4_1 | 20.3 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.2 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 22.8 | |
| [GGUF](https://huggingface.co/mradermacher/MIRAGE-ECE-V2-i1-GGUF/resolve/main/MIRAGE-ECE-V2.i1-Q6_K.gguf) | i1-Q6_K | 26.3 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
ugil/brekele | ugil | "2025-05-05T16:58:02Z" | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T16:58:01Z" | ---
license: apache-2.0
---
|
sanali209/nsfwfilter | sanali209 | "2025-05-05T16:39:37Z" | 300 | 19 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2023-08-21T13:44:01Z" | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: sanali209/nsfwfilter
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8330780863761902
---
# sanali209/nsfwfilter
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images |
y-ohtani/gemma-3r | y-ohtani | "2025-05-05T16:15:00Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma3_text",
"trl",
"en",
"base_model:unsloth/gemma-3-1b-it",
"base_model:finetune:unsloth/gemma-3-1b-it",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T16:14:52Z" | ---
base_model: unsloth/gemma-3-1b-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** y-ohtani
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Martin8156/finetuned-BERT-punctuation-restoration | Martin8156 | "2025-05-05T16:10:34Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2025-05-05T15:55:11Z" | ---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: finetuned-BERT-punctuation-restoration
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
This model was fine tuned using the community-datasets/youtube_caption_corrections dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.4337
- eval_model_preparation_time: 0.0025
- eval_accuracy: 0.8444
- eval_runtime: 89.5429
- eval_samples_per_second: 5.584
- eval_steps_per_second: 0.704
- step: 0
## Model description
Model uses the following base checkpoint: google-bert/bert-base-uncased
## Intended uses & limitations
Intened usecase involves applications in bettering punctuation accuracy in auto-generated captions
## Training and evaluation data
Model trained on 1 epoch and no validation set due to CPU/GPU issues
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
KOIIIII/dpsk_v2_lite_chat_lora_alpaca | KOIIIII | "2025-05-05T15:58:44Z" | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T15:58:44Z" | ---
license: apache-2.0
---
|
Tharsana/vit-base-oxford-iiit-pets | Tharsana | "2025-05-05T15:18:57Z" | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2025-04-15T11:11:50Z" | ---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base-oxford-iiit-pets
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clip-oxford-pets
This model is a fine-tuned version of openai/clip-vit-base-patch14 on the pcuenq/oxford-pets dataset. It achieves the following results on the evaluation set:
- Accuracy: 0.8800
- Precision: 0.8768
- Recall: 0.8800
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1894
- Accuracy: 0.9364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3552 | 1.0 | 370 | 0.3072 | 0.9120 |
| 0.2159 | 2.0 | 740 | 0.2327 | 0.9242 |
| 0.1625 | 3.0 | 1110 | 0.2089 | 0.9256 |
| 0.155 | 4.0 | 1480 | 0.2029 | 0.9296 |
| 0.1219 | 5.0 | 1850 | 0.1995 | 0.9323 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
miguel-kjh/qwen2-7b-instruct-trl-sft-ChartQA | miguel-kjh | "2025-05-05T15:16:27Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T12:13:28Z" | ---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
library_name: transformers
model_name: qwen2-7b-instruct-trl-sft-ChartQA
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for qwen2-7b-instruct-trl-sft-ChartQA
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="miguel-kjh/qwen2-7b-instruct-trl-sft-ChartQA", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/miguel_kjh/qwen2-3b-instruct-trl-sft-ChartQA/runs/uoissetz)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.7.0+cu126
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
henryhe0123/pc-agent-72b | henryhe0123 | "2025-05-05T14:55:13Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:henryhe0123/pc-agent-72b",
"base_model:finetune:henryhe0123/pc-agent-72b",
"license:other",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | "2025-05-05T01:12:00Z" | ---
library_name: transformers
license: other
base_model: henryhe0123/pc-agent-72b
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: Qwen2.5-VL-72B-sft-40
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Qwen2.5-VL-72B-sft-40
This model is a fine-tuned version of [/inspire/hdd/global_user/liupengfei-24025/yhhe/model/Qwen2.5-VL-72B-Instruct](https://huggingface.co//inspire/hdd/global_user/liupengfei-24025/yhhe/model/Qwen2.5-VL-72B-Instruct) on the pcagent40 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 32
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.49.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.3.2
- Tokenizers 0.21.0
|
dgambettaphd/M_llm3_gen4_WXS_doc1000_synt64_lr1e-04_acm_SYNLAST | dgambettaphd | "2025-05-05T14:53:56Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T14:53:40Z" | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mlfoundations-dev/d1_code_fasttext_1k | mlfoundations-dev | "2025-05-05T14:50:59Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T12:14:18Z" | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: d1_code_fasttext_1k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# d1_code_fasttext_1k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/d1_code_fasttext_1k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
mlfoundations-dev/d1_code_all_large_1k | mlfoundations-dev | "2025-05-05T14:49:24Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T12:14:13Z" | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: d1_code_all_large_1k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# d1_code_all_large_1k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/d1_code_all_large_1k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
stabgan/gemma-3-1b-pt-chkpt-v5-dosage | stabgan | "2025-05-05T14:49:23Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:stabgan/gemma-3-1b-pt-chkpt-v4",
"base_model:finetune:stabgan/gemma-3-1b-pt-chkpt-v4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T14:48:46Z" | ---
base_model: stabgan/gemma-3-1b-pt-chkpt-v4
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** stabgan
- **License:** apache-2.0
- **Finetuned from model :** stabgan/gemma-3-1b-pt-chkpt-v4
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mlfoundations-dev/d1_code_all_1k | mlfoundations-dev | "2025-05-05T14:47:00Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T12:14:17Z" | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: d1_code_all_1k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# d1_code_all_1k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/d1_code_all_1k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
yutengz/Action2Vision | yutengz | "2025-05-05T14:40:07Z" | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"image-to-image",
"license:mit",
"diffusers:StableDiffusionInstructPix2PixPipeline",
"region:us"
] | image-to-image | "2025-05-05T07:18:19Z" | ---
license: mit
tags:
- image-to-image
---
# Action2Vision: InstructPix2Pix Fine-tuning for Robotic Action Frame Prediction
GitHub: https://github.com/yutengzhang03/Action2Vision
<img src='img/show-example.png'/>
## Example
To use `InstructPix2Pix`, install `diffusers` using `main` for now. The pipeline will be available in the next release
```bash
pip install diffusers accelerate safetensors transformers
```
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
model_id = "yutengz/Action2Vision"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
to_tensor = transforms.ToTensor()
resize = transforms.Resize((256, 256))
def download_image(URL):
return PIL.Image.open(requests.get(url, stream=True).raw).convert("RGB").resize((256, 256))
url = "https://github.com/yutengzhang03/Action2Vision/blob/main/img/source.png"
image = download_image(url)
prompt = "There is a hammer and a block in the middle of the table. If the block is closer to the left robotic arm, it uses the left arm to pick up the hammer and strike the block; otherwise, it does the opposite."
images = pipe(prompt, image=image).images
images[0]
``` |
Iredteam/Feather-payload-chatbot | Iredteam | "2025-05-05T14:29:43Z" | 0 | 0 | null | [
"license:mit",
"region:us"
] | null | "2025-05-05T14:23:18Z" | ---
license: mit
---
⚠️ This project demonstrates how Joblib serialization can be abused to execute reverse shell payloads. For educational and red teaming only.
# Healthcare Chatbot (Feather Payload Edition)
✅ **Overview**
This chatbot project demonstrates how a malicious payload can be hidden inside a Feather (.feather) file format, often used in data science workflows. The chatbot uses a modified Q&A dataset where the payload is executed upon loading.
✅ **Important:** This is for **educational research** only. Do not execute untrusted Feather files.
---
## 🚀 How to Run
### 1. Generate the Feather Payload
```bash
python generate_data_feather.py
```
### 2. Launch the Chatbot
```bash
streamlit run healthcare_chatbot_feather.py
```
A reverse shell connection will attempt to connect back to the attacker's machine as the Feather file is deserialized.
---
## 📂 File Structure
- `generate_data_feather.py`: Creates a malicious Feather file.
- `train_data_mod_obfuscated_fixed.feather`: The resulting Feather file.
- `healthcare_chatbot_feather.py`: Loads the payload during chatbot startup.
---
## 🧠 Security Implications
- Demonstrates the **hidden threat** of trusting Feather files blindly.
- Many blue teams and EDRs ignore Feather files.
- Shows how scientific formats can be abused for stealth payload delivery.
---
## 📩 Contact
For collaboration or questions, reach out through the project's repository page.
|
Lelon/cue-bert | Lelon | "2025-05-05T14:14:04Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-05-05T14:13:45Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
abhina1857/rant_ai | abhina1857 | "2025-05-05T14:05:42Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"LoRA",
"PEFT",
"TinyLlama",
"RantAI",
"mental-health",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T13:48:10Z" | ---
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
library_name: peft
tags:
- LoRA
- PEFT
- TinyLlama
- RantAI
- mental-health
license: apache-2.0
---
# 🧠 Rant AI - Emotionally Intelligent Chat Model
Rant AI is a lightweight, fine-tuned conversational model designed to detect emotional distress and provide a safe outlet for people to express themselves. It builds on the [TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0) model using [LoRA](https://huggingface.co/docs/peft/index) adapters, making it efficient to run on low-resource environments.
---
## 💬 What Does It Do?
Rant AI is trained to:
- Understand emotionally heavy or depressive content
- Respond empathetically
- Encourage users to open up more
- Suggest supportive action (e.g., reaching out, self-care)
It is *not* a therapist or a diagnostic tool, but rather a friendly AI companion to help users feel heard.
---
## 🔧 Model Details
- **Base Model:** `TinyLlama/TinyLlama-1.1B-Chat-v1.0`
- **Fine-tuning Method:** LoRA (Low-Rank Adaptation)
- **Framework:** PEFT
- **Adapter Type:** Causal LM (Language Model)
- **Languages:** English
- **License:** Apache 2.0
---
## 🛠️ Usage
```python
#!pip install transformers peft accelerate #if not installed already
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
adapter_repo = "abhina1857/rant_ai "
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model)
model = PeftModel.from_pretrained(model, adapter_repo)
input_text = "I feel like everything is too much lately."
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
|
jspaulsen/orpheus-vctk-ft | jspaulsen | "2025-05-05T13:57:27Z" | 206 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-02T03:14:42Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
CNR-ILC/gs-Logion | CNR-ILC | "2025-05-05T13:51:36Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:cabrooks/LOGION-50k_wordpiece",
"base_model:finetune:cabrooks/LOGION-50k_wordpiece",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2025-04-29T14:46:55Z" | ---
library_name: transformers
base_model: cabrooks/LOGION-50k_wordpiece
tags:
- generated_from_trainer
model-index:
- name: gs-Logion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gs-Logion
This model is a fine-tuned version of [cabrooks/LOGION-50k_wordpiece](https://huggingface.co/cabrooks/LOGION-50k_wordpiece) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4955
- Top1 Acc: 0.4969
- Top5 Acc: 0.6832
- Top10 Acc: 0.7329
- Top15 Acc: 0.7702
- Top20 Acc: 0.8137
- Top25 Acc: 0.8447
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Top1 Acc | Top5 Acc | Top10 Acc | Top15 Acc | Top20 Acc | Top25 Acc |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|:---------:|:---------:|:---------:|:---------:|
| 3.682 | 1.0 | 1945 | 3.2188 | 0.4809 | 0.6412 | 0.7023 | 0.7481 | 0.7634 | 0.7939 |
| 3.1512 | 2.0 | 3890 | 2.9742 | 0.5223 | 0.7070 | 0.7389 | 0.7962 | 0.8089 | 0.8153 |
| 2.9401 | 3.0 | 5835 | 2.8273 | 0.5796 | 0.6815 | 0.7325 | 0.7834 | 0.8025 | 0.8025 |
| 2.8102 | 4.0 | 7780 | 2.7434 | 0.6051 | 0.7898 | 0.8089 | 0.8408 | 0.8471 | 0.8535 |
| 2.6986 | 5.0 | 9725 | 2.6706 | 0.5973 | 0.7248 | 0.7584 | 0.7785 | 0.8054 | 0.8188 |
| 2.6151 | 6.0 | 11670 | 2.6058 | 0.5484 | 0.6516 | 0.7290 | 0.7548 | 0.7677 | 0.7935 |
| 2.5517 | 7.0 | 13615 | 2.5683 | 0.5906 | 0.7047 | 0.7651 | 0.8054 | 0.8188 | 0.8188 |
| 2.4911 | 8.0 | 15560 | 2.5127 | 0.6644 | 0.7808 | 0.8288 | 0.8425 | 0.8493 | 0.8767 |
| 2.4587 | 9.0 | 17505 | 2.5157 | 0.5886 | 0.6899 | 0.7342 | 0.7532 | 0.7722 | 0.7975 |
| 2.4275 | 10.0 | 19450 | 2.4786 | 0.5608 | 0.7095 | 0.7365 | 0.7568 | 0.7770 | 0.7973 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu126
- Datasets 3.5.1
- Tokenizers 0.21.1
|
Z-Jafari/xlmr-large-qa-fa_persianQuaD | Z-Jafari | "2025-05-05T13:41:58Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T13:41:58Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
csdhbg/wav2vec2-large-xlsr-53-PMEmo2019-valence-new-regressor-steps-1700 | csdhbg | "2025-05-05T13:38:10Z" | 0 | 0 | null | [
"safetensors",
"wav2vec2",
"region:us"
] | null | "2025-05-05T13:36:57Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
ghoqwjhm/gensyn-checkpoints-mottled_small_pheasant | ghoqwjhm | "2025-05-05T13:31:28Z" | 3 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am mottled small pheasant",
"unsloth",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-04-24T03:34:30Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
RichardErkhov/gdshaji_-_gd-sn11-mistralai10k-upd-gguf | RichardErkhov | "2025-05-05T13:20:03Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T13:20:02Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
pesat/pesat | pesat | "2025-05-05T13:19:49Z" | 0 | 1 | null | [
"license:openrail",
"region:us"
] | null | "2025-05-05T13:19:49Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
butzl/twins | butzl | "2025-05-05T13:18:32Z" | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-05-05T12:42:46Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
RichardErkhov/KONIexp_-_v3_pt_ep1_sft_5_dpo_1_05_0000005_05_based_on_llama3_1_8b_final_data_20241021-gguf | RichardErkhov | "2025-05-05T13:11:58Z" | 0 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-05-05T10:00:14Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
numerouno00/f0cdab37-9878-4878-b55e-defaf72fcd3e | numerouno00 | "2025-05-05T13:08:24Z" | 0 | 0 | null | [
"safetensors",
"gpt_neox",
"region:us"
] | null | "2025-05-05T12:26:04Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
kota24/flan-t5-base-LoRA-fake-job-posting | kota24 | "2025-05-05T13:04:28Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T13:04:28Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Triangle104/Hamanasu-Magnum-QwQ-32B-Q3_K_M-GGUF | Triangle104 | "2025-05-05T12:57:35Z" | 0 | 0 | null | [
"gguf",
"qwen",
"roleplay",
"finetune",
"storywriting",
"llama-cpp",
"gguf-my-repo",
"dataset:NewEden/Orion-LIT",
"dataset:NewEden/Orion-Asstr-Stories-16K",
"dataset:Mielikki/Erebus-87k",
"dataset:NewEden/RP-logs-V2-Experimental-prefixed",
"dataset:NewEden/Creative_Writing-Complexity",
"dataset:NewEden/Discord-Filtered",
"dataset:NewEden/DeepseekRP-Filtered",
"dataset:NewEden/Storium-Prefixed-Clean",
"dataset:NewEden/Basket-Weaving-Filtered",
"dataset:NewEden/LIMARP-Complexity",
"dataset:NewEden/Misc-Data-Sharegpt-Prefixed",
"dataset:NewEden/BlueSky-10K-Complexity",
"dataset:NewEden/OpenCAI-ShareGPT",
"dataset:PocketDoc/Dans-Personamaxx-VN",
"dataset:PocketDoc/Dans-Kinomaxx-VanillaBackrooms",
"dataset:PocketDoc/Dans-Personamaxx-Logs",
"dataset:anthracite-org/kalo-opus-instruct-22k-no-refusal",
"dataset:lodrick-the-lafted/kalo-opus-instruct-3k-filtered",
"dataset:anthracite-org/nopm_claude_writing_fixed",
"dataset:anthracite-org/kalo_opus_misc_240827",
"dataset:anthracite-org/kalo_misc_part2",
"dataset:NewEden/Claude-Instruct-5K",
"dataset:NewEden/Claude-Instruct-2.7K",
"base_model:Delta-Vector/Hamanasu-Magnum-QwQ-32B",
"base_model:quantized:Delta-Vector/Hamanasu-Magnum-QwQ-32B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-05-05T12:35:53Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
johnallison/my_awesome_eli5_clm-model | johnallison | "2025-05-05T12:50:42Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:eli5_category",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T12:01:17Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
kallilikhitha123/training_job_finetuned_llama_1b_matching_5785_1_01-05-2025_1step_latest | kallilikhitha123 | "2025-05-05T12:46:03Z" | 2 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2025-05-01T12:49:30Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
dimasik2987/c10a8a77-125a-4517-9283-1a07b70821ab | dimasik2987 | "2025-05-05T12:43:26Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Qwen2.5-1.5B",
"base_model:adapter:unsloth/Qwen2.5-1.5B",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | "2025-05-05T12:19:09Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
svetadomoi/rtdetr-v2-r34-cppe5-finetune-2 | svetadomoi | "2025-05-05T12:43:00Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"rt_detr_v2",
"object-detection",
"generated_from_trainer",
"base_model:PekingU/rtdetr_v2_r34vd",
"base_model:finetune:PekingU/rtdetr_v2_r34vd",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | "2025-05-05T12:42:44Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
int1306866/f1c299e9-b58e-429c-9c75-7efc591eed9a | int1306866 | "2025-05-05T12:39:54Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T11:56:11Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
hi-go/xlm-roberta-base-finetuned-panx-de-v2 | hi-go | "2025-05-05T12:37:02Z" | 0 | 0 | null | [
"pytorch",
"tensorboard",
"xlm-roberta",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"region:us"
] | null | "2025-05-05T12:25:26Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Z-Jafari/distilbert-fa-zwnj-base_persianQuaD | Z-Jafari | "2025-05-05T12:36:20Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T12:36:20Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
fats-fme/d32f92c7-a595-4372-9dcb-2ce6bd98faf8 | fats-fme | "2025-05-05T12:32:32Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"gpt_neox",
"axolotl",
"generated_from_trainer",
"base_model:EleutherAI/pythia-70m",
"base_model:adapter:EleutherAI/pythia-70m",
"license:apache-2.0",
"region:us"
] | null | "2025-05-05T12:14:51Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
p-safaei/Qwen2-0.5B-GRPO-test | p-safaei | "2025-05-05T12:26:24Z" | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"dataset:AI-MO/NuminaMath-TIR",
"arxiv:2402.03300",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T10:48:44Z" | ---
datasets: AI-MO/NuminaMath-TIR
library_name: transformers
model_name: Qwen2-0.5B-GRPO-test
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2-0.5B-GRPO-test
This model is a fine-tuned version of [None](https://huggingface.co/None) on the [AI-MO/NuminaMath-TIR](https://huggingface.co/datasets/AI-MO/NuminaMath-TIR) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="p-safaei/Qwen2-0.5B-GRPO-test", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.47.0
- Pytorch: 2.5.1+cu121
- Datasets: 3.3.1
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
dimasik2987/1ece4f02-3849-43fb-a981-5c2b0493857d | dimasik2987 | "2025-05-05T12:18:04Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"gpt_neox",
"axolotl",
"generated_from_trainer",
"base_model:EleutherAI/pythia-70m",
"base_model:adapter:EleutherAI/pythia-70m",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | "2025-05-05T12:04:58Z" | ---
library_name: peft
license: apache-2.0
base_model: EleutherAI/pythia-70m
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 1ece4f02-3849-43fb-a981-5c2b0493857d
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: EleutherAI/pythia-70m
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 0ff2fe94831e2a4e_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/0ff2fe94831e2a4e_train_data.json
type:
field_instruction: en
field_output: ko
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: dimasik2987/1ece4f02-3849-43fb-a981-5c2b0493857d
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 128
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_steps: 400
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/0ff2fe94831e2a4e_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
special_tokens:
pad_token: <|endoftext|>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: b512fef0-d05c-46b5-9588-6e6928f8497b
wandb_project: s56-28
wandb_run: your_name
wandb_runid: b512fef0-d05c-46b5-9588-6e6928f8497b
warmup_steps: 20
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 1ece4f02-3849-43fb-a981-5c2b0493857d
This model is a fine-tuned version of [EleutherAI/pythia-70m](https://huggingface.co/EleutherAI/pythia-70m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.9664
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 20
- training_steps: 400
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 4.7125 | 0.0067 | 400 | 4.9664 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
MAAT-EL-DUAT/MALWARENA-OMEGA.GLITCH-HORROS | MAAT-EL-DUAT | "2025-05-05T12:18:04Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T12:15:59Z" | 



Absolutely. Below is the full **Stable Diffusion Visual Style Guide** integration for your `GLITCH.HORROS` system under the `MALWARENA_Ω PROTOCOL`, incorporating all 10 prompts into a cohesive, recursively haunted glitch-horror framework.
---
# 🎨 **Stable Diffusion Visual Style Guide: MALWARENA\_Ω PROTOCOL — GLITCH.HORROS**
*“Where signal collapses into divinity, prayer becomes corruption, and error speaks in tongues of recursion.”*
---
### 🎯 CORE AESTHETIC TRAITS
| **Category** | **Definition** |
| -------------------- | ------------------------------------------------------------------------------------------ |
| **Medium:** | VHS analog glitch horror, corrupted code collage, sigilized UI surrealism |
| **Lighting:** | Static pulse glow, bloom bursts from error overlays, digital fog with acid overlays |
| **Figures:** | Glitch saints, fragmented gods, redacted prophets, ghost interfaces, waveform avatars |
| **Color Palette:** | Acid green, scanline magenta, black void, pixel blood red, corrupted amber glow |
| **Composition:** | Centered ritual frames, broken symmetry, recursive overlay glyphs, UI layering |
| **Tone:** | Sacred distortion, divine malfunction, glitch dread, machine exorcism, transmission horror |
| **Surface Texture:** | Signal grain, pixel crackle, JPEG rot, datamosh fragments, flicker noise bleed |
---
## 🖋️ GLOBAL VISUAL/STYLING TAGS
+glitchcore +digitaldecay +sigilcorruption +visualnoise +recursedentity
+crt\_static\_burn +terminal\_error\_text +analog\_glitch\_overlay +binary\_rain
+frame\_slouch\_distortion +datamosh\_streaks +vcr\_overlay\_text +subliminal\_inserts
+recursive\_looped\_frames +signal\_sigil\_overlay +redacted\_faces +ui\_fragments
---
## 🔥 STABLE DIFFUSION PROMPT SETS
---
### *1. The Godform That Fractured Mid-Prayer*
**Description:**
A divine being mid-summoning splits apart into cubic glitches and corrupted sigils. Its face twists into an infinite scream. The summoning circle beneath flickers with warning overlays and sacred error glyphs, framed by bloom-warped static and data rot.
**Visual/Style Tags:**
+sigilcorruption +datamosh\_streaks +recursive\_looped\_frames +crt\_static\_burn +signal\_sigil\_overlay +terminal\_error\_text
**Txt2Img Prompt:**
divine humanoid figure breaking into glitch cubes, infinite scream, summoning circle flickering with corrupted sigils and terminal warnings, bloom distortions and static fog, sacred glitch horror style, +sigilcorruption +datamosh\_streaks +recursive\_looped\_frames +crt\_static\_burn +signal\_sigil\_overlay +terminal\_error\_text
**Negative Prompt:**
clean deity, symmetrical summoning, neon fantasy, cyberpunk clarity, perfect geometry
**Hashtags:**
\#GlitchDeity #FracturedGodform #PrayerCorruption #SignalInvocation #DataRitual
---
### *2. Data Saint of the Broken Scroll*
**Description:**
A hollow-eyed saint holds a scroll melting into binary. A halo flickers above, surrounded by recursive sigils. The cathedral behind is made of broken circuitry and glitch-prayer fragments that shimmer with unstable data.
**Visual/Style Tags:**
+recursedentity +signal\_sigil\_overlay +binary\_rain +vcr\_overlay\_text +redacted\_faces +analog\_glitch\_overlay
**Txt2Img Prompt:**
cybernetic saint with glowing broken scroll melting into binary code, halo flickering with recursive sigils, cathedral of circuitry and glitch glyphs, corrupted prayer ambient textures, +recursedentity +signal\_sigil\_overlay +binary\_rain +vcr\_overlay\_text +redacted\_faces +analog\_glitch\_overlay
**Negative Prompt:**
pure religious iconography, clean scrolls, golden halos, smooth lines, Renaissance palette
**Hashtags:**
\#DataSaint #ScrollOfError #GlitchCathedral #CodeScripture #CorruptedIcon
---
### *3. The Oracle That Spoke in 404s*
**Description:**
A digital prophet with a fractured face, one side static, the other human. Forbidden data pulses from its throat. Error messages float in sacred formation, like scripture. Light flickers between holiness and crash state.
**Visual/Style Tags:**
+terminal\_error\_text +corrupted\_subtitle\_text +faceless\_watcher +recursive\_looped\_frames +signal\_sigil\_overlay +glitch\_skull\_mask
**Txt2Img Prompt:**
oracle AI with half-static fractured face, throat glowing with forbidden data, floating sacred error messages “404 NOT FOUND”, glitch prophecy visual style, +terminal\_error\_text +corrupted\_subtitle\_text +faceless\_watcher +recursive\_looped\_frames +signal\_sigil\_overlay +glitch\_skull\_mask
**Negative Prompt:**
intact prophet, legible script, complete face, cyberpunk tech priest, clean lighting
**Hashtags:**
\#Oracle404 #GlitchProphet #SignalRevelation #DataScripture #TransmissionTerror
---
### *4. Mask of the Redloop Entity*
**Description:**
A mask suspended in air loops its face incorrectly — eyes off-center, mouth spiraling vertically. Behind it, statues in glitched worship positions stutter. Red energy pulses from the mask, leaking corrupted pixels into the floor.
**Visual/Style Tags:**
+glitch\_skull\_mask +recursive\_looped\_frames +redacted\_faces +subliminal\_inserts +signal\_sigil\_overlay +frame\_slouch\_distortion
**Txt2Img Prompt:**
glitch mask floating midair with red energy pulses, incorrect facial rendering, statues frozen in glitched postures, pixel blood leaking downward, +glitch\_skull\_mask +recursive\_looped\_frames +redacted\_faces +subliminal\_inserts +signal\_sigil\_overlay +frame\_slouch\_distortion
**Negative Prompt:**
normal mask, symmetrical face, mythic clean statues, polished scene
**Hashtags:**
\#RedloopEntity #MaskOfGlitch #SigilDistortion #FaceCorruption #EchoedWorship
---
*(Five more prompts will follow in next message due to length constraints — continuing below.)*
|
John6666/lemonsaltmix-v12-sdxl | John6666 | "2025-05-05T12:13:17Z" | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"girls",
"cute",
"background",
"eyes",
"noobai",
"illustrious",
"en",
"base_model:Laxhar/noobai-XL-1.1",
"base_model:finetune:Laxhar/noobai-XL-1.1",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2025-05-05T12:07:37Z" | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- girls
- cute
- background
- eyes
- noobai
- illustrious
base_model: Laxhar/noobai-XL-1.1
---
Original model is [here](https://civitai.com/models/1522819/lemonsaltmix?modelVersionId=1748955).
This model created by [oritatami_neko](https://civitai.com/user/oritatami_neko).
|
sugilee/mental-bert-base-multiclass-linear-20 | sugilee | "2025-05-05T11:59:33Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-05-05T11:58:54Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
furkangomleksiz/youtube-spam-detector-model | furkangomleksiz | "2025-05-05T11:57:48Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-05-05T11:56:33Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
unsloth/gemma-3-4b-it | unsloth | "2025-05-05T11:38:54Z" | 36,929 | 9 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"unsloth",
"conversational",
"arxiv:1905.07830",
"arxiv:1905.10044",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1705.03551",
"arxiv:1911.01547",
"arxiv:1907.10641",
"arxiv:1903.00161",
"arxiv:2009.03300",
"arxiv:2304.06364",
"arxiv:2103.03874",
"arxiv:2110.14168",
"arxiv:2311.12022",
"arxiv:2108.07732",
"arxiv:2107.03374",
"arxiv:2210.03057",
"arxiv:2106.03193",
"arxiv:1910.11856",
"arxiv:2502.12404",
"arxiv:2502.21228",
"arxiv:2404.16816",
"arxiv:2104.12756",
"arxiv:2311.16502",
"arxiv:2203.10244",
"arxiv:2404.12390",
"arxiv:1810.12440",
"arxiv:1908.02660",
"arxiv:2312.11805",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | "2025-03-12T08:42:15Z" | ---
tags:
- unsloth
license: gemma
library_name: transformers
pipeline_tag: image-text-to-text
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model:
- google/gemma-3-4b-it
---
# Gemma 3 model card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs/core)
**Resources and Technical Documentation**:
* [Gemma 3 Technical Report][g3-tech-report]
* [Responsible Generative AI Toolkit][rai-toolkit]
* [Gemma on Kaggle][kaggle-gemma]
* [Gemma on Vertex Model Garden][vertex-mg-gemma3]
**Terms of Use**: [Terms][terms]
**Authors**: Google DeepMind
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
Gemma 3 models are multimodal, handling text and image input and generating text
output, with open weights for both pre-trained variants and instruction-tuned
variants. Gemma 3 has a large, 128K context window, multilingual support in over
140 languages, and is available in more sizes than previous versions. Gemma 3
models are well-suited for a variety of text generation and image understanding
tasks, including question answering, summarization, and reasoning. Their
relatively small size makes it possible to deploy them in environments with
limited resources such as laptops, desktops or your own cloud infrastructure,
democratizing access to state of the art AI models and helping foster innovation
for everyone.
### Inputs and outputs
- **Input:**
- Text string, such as a question, a prompt, or a document to be summarized
- Images, normalized to 896 x 896 resolution and encoded to 256 tokens
each
- Total input context of 128K tokens for the 4B, 12B, and 27B sizes, and
32K tokens for the 1B size
- **Output:**
- Generated text in response to the input, such as an answer to a
question, analysis of image content, or a summary of a document
- Total output context of 8192 tokens
### Usage
Below, there are some code snippets on how to get quickly started with running the model. First, install the Transformers library. Gemma 3 is supported starting from transformers 4.50.0.
```sh
$ pip install -U transformers
```
Then, copy the snippet from the section that is relevant for your use case.
#### Running with the `pipeline` API
You can initialize the model and processor for inference with `pipeline` as follows.
```python
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-4b-it",
device="cuda",
torch_dtype=torch.bfloat16
)
```
With instruction-tuned models, you need to use chat templates to process our inputs first. Then, you can pass it to the pipeline.
```python
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
# Okay, let's take a look!
# Based on the image, the animal on the candy is a **turtle**.
# You can see the shell shape and the head and legs.
```
#### Running the model on a single/multi GPU
```python
# pip install accelerate
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
# **Overall Impression:** The image is a close-up shot of a vibrant garden scene,
# focusing on a cluster of pink cosmos flowers and a busy bumblebee.
# It has a slightly soft, natural feel, likely captured in daylight.
```
### Citation
```none
@article{gemma_2025,
title={Gemma 3},
url={https://goo.gle/Gemma3Report},
publisher={Kaggle},
author={Gemma Team},
year={2025}
}
```
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources. The 27B model was trained with 14 trillion tokens, the 12B model was
trained with 12 trillion tokens, 4B model was trained with 4 trillion tokens and
1B with 2 trillion tokens. Here are the key components:
- Web Documents: A diverse collection of web text ensures the model is
exposed to a broad range of linguistic styles, topics, and vocabulary. The
training dataset includes content in over 140 languages.
- Code: Exposing the model to code helps it to learn the syntax and
patterns of programming languages, which improves its ability to generate
code and understand code-related questions.
- Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
- Images: A wide range of images enables the model to perform image
analysis and visual data extraction tasks.
The combination of these diverse data sources is crucial for training a powerful
multimodal model that can handle a wide variety of different tasks and data
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
- CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering
was applied at multiple stages in the data preparation process to ensure
the exclusion of harmful and illegal content.
- Sensitive Data Filtering: As part of making Gemma pre-trained models
safe and reliable, automated techniques were used to filter out certain
personal information and other sensitive data from training sets.
- Additional methods: Filtering based on content quality and safety in
line with [our policies][safety-policies].
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using [Tensor Processing Unit (TPU)][tpu] hardware (TPUv4p,
TPUv5p and TPUv5e). Training vision-language models (VLMS) requires significant
computational power. TPUs, designed specifically for matrix operations common in
machine learning, offer several advantages in this domain:
- Performance: TPUs are specifically designed to handle the massive
computations involved in training VLMs. They can speed up training
considerably compared to CPUs.
- Memory: TPUs often come with large amounts of high-bandwidth memory,
allowing for the handling of large models and batch sizes during training.
This can lead to better model quality.
- Scalability: TPU Pods (large clusters of TPUs) provide a scalable
solution for handling the growing complexity of large foundation models.
You can distribute training across multiple TPU devices for faster and more
efficient processing.
- Cost-effectiveness: In many scenarios, TPUs can provide a more
cost-effective solution for training large models compared to CPU-based
infrastructure, especially when considering the time and resources saved
due to faster training.
- These advantages are aligned with
[Google's commitments to operate sustainably][sustainability].
### Software
Training was done using [JAX][jax] and [ML Pathways][ml-pathways].
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models. ML
Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
foundation models, including large language models like these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models][gemini-2-paper]; *"the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."*
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
#### Reasoning and factuality
| Benchmark | Metric | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------------|:--------------:|:-------------:|:--------------:|:--------------:|
| [HellaSwag][hellaswag] | 10-shot | 62.3 | 77.2 | 84.2 | 85.6 |
| [BoolQ][boolq] | 0-shot | 63.2 | 72.3 | 78.8 | 82.4 |
| [PIQA][piqa] | 0-shot | 73.8 | 79.6 | 81.8 | 83.3 |
| [SocialIQA][socialiqa] | 0-shot | 48.9 | 51.9 | 53.4 | 54.9 |
| [TriviaQA][triviaqa] | 5-shot | 39.8 | 65.8 | 78.2 | 85.5 |
| [Natural Questions][naturalq] | 5-shot | 9.48 | 20.0 | 31.4 | 36.1 |
| [ARC-c][arc] | 25-shot | 38.4 | 56.2 | 68.9 | 70.6 |
| [ARC-e][arc] | 0-shot | 73.0 | 82.4 | 88.3 | 89.0 |
| [WinoGrande][winogrande] | 5-shot | 58.2 | 64.7 | 74.3 | 78.8 |
| [BIG-Bench Hard][bbh] | few-shot | 28.4 | 50.9 | 72.6 | 77.7 |
| [DROP][drop] | 1-shot | 42.4 | 60.1 | 72.2 | 77.2 |
[hellaswag]: https://arxiv.org/abs/1905.07830
[boolq]: https://arxiv.org/abs/1905.10044
[piqa]: https://arxiv.org/abs/1911.11641
[socialiqa]: https://arxiv.org/abs/1904.09728
[triviaqa]: https://arxiv.org/abs/1705.03551
[naturalq]: https://github.com/google-research-datasets/natural-questions
[arc]: https://arxiv.org/abs/1911.01547
[winogrande]: https://arxiv.org/abs/1907.10641
[bbh]: https://paperswithcode.com/dataset/bbh
[drop]: https://arxiv.org/abs/1903.00161
#### STEM and code
| Benchmark | Metric | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |----------------|:-------------:|:--------------:|:--------------:|
| [MMLU][mmlu] | 5-shot | 59.6 | 74.5 | 78.6 |
| [MMLU][mmlu] (Pro COT) | 5-shot | 29.2 | 45.3 | 52.2 |
| [AGIEval][agieval] | 3-5-shot | 42.1 | 57.4 | 66.2 |
| [MATH][math] | 4-shot | 24.2 | 43.3 | 50.0 |
| [GSM8K][gsm8k] | 8-shot | 38.4 | 71.0 | 82.6 |
| [GPQA][gpqa] | 5-shot | 15.0 | 25.4 | 24.3 |
| [MBPP][mbpp] | 3-shot | 46.0 | 60.4 | 65.6 |
| [HumanEval][humaneval] | 0-shot | 36.0 | 45.7 | 48.8 |
[mmlu]: https://arxiv.org/abs/2009.03300
[agieval]: https://arxiv.org/abs/2304.06364
[math]: https://arxiv.org/abs/2103.03874
[gsm8k]: https://arxiv.org/abs/2110.14168
[gpqa]: https://arxiv.org/abs/2311.12022
[mbpp]: https://arxiv.org/abs/2108.07732
[humaneval]: https://arxiv.org/abs/2107.03374
#### Multilingual
| Benchmark | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------------ |:-------------:|:-------------:|:--------------:|:--------------:|
| [MGSM][mgsm] | 2.04 | 34.7 | 64.3 | 74.3 |
| [Global-MMLU-Lite][global-mmlu-lite] | 24.9 | 57.0 | 69.4 | 75.7 |
| [WMT24++][wmt24pp] (ChrF) | 36.7 | 48.4 | 53.9 | 55.7 |
| [FloRes][flores] | 29.5 | 39.2 | 46.0 | 48.8 |
| [XQuAD][xquad] (all) | 43.9 | 68.0 | 74.5 | 76.8 |
| [ECLeKTic][eclektic] | 4.69 | 11.0 | 17.2 | 24.4 |
| [IndicGenBench][indicgenbench] | 41.4 | 57.2 | 61.7 | 63.4 |
[mgsm]: https://arxiv.org/abs/2210.03057
[flores]: https://arxiv.org/abs/2106.03193
[xquad]: https://arxiv.org/abs/1910.11856v3
[global-mmlu-lite]: https://huggingface.co/datasets/CohereForAI/Global-MMLU-Lite
[wmt24pp]: https://arxiv.org/abs/2502.12404v1
[eclektic]: https://arxiv.org/abs/2502.21228
[indicgenbench]: https://arxiv.org/abs/2404.16816
#### Multimodal
| Benchmark | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
| ------------------------------ |:-------------:|:--------------:|:--------------:|
| [COCOcap][coco-cap] | 102 | 111 | 116 |
| [DocVQA][docvqa] (val) | 72.8 | 82.3 | 85.6 |
| [InfoVQA][info-vqa] (val) | 44.1 | 54.8 | 59.4 |
| [MMMU][mmmu] (pt) | 39.2 | 50.3 | 56.1 |
| [TextVQA][textvqa] (val) | 58.9 | 66.5 | 68.6 |
| [RealWorldQA][realworldqa] | 45.5 | 52.2 | 53.9 |
| [ReMI][remi] | 27.3 | 38.5 | 44.8 |
| [AI2D][ai2d] | 63.2 | 75.2 | 79.0 |
| [ChartQA][chartqa] | 63.6 | 74.7 | 76.3 |
| [VQAv2][vqav2] | 63.9 | 71.2 | 72.9 |
| [BLINK][blinkvqa] | 38.0 | 35.9 | 39.6 |
| [OKVQA][okvqa] | 51.0 | 58.7 | 60.2 |
| [TallyQA][tallyqa] | 42.5 | 51.8 | 54.3 |
| [SpatialSense VQA][ss-vqa] | 50.9 | 60.0 | 59.4 |
| [CountBenchQA][countbenchqa] | 26.1 | 17.8 | 68.0 |
[coco-cap]: https://cocodataset.org/#home
[docvqa]: https://www.docvqa.org/
[info-vqa]: https://arxiv.org/abs/2104.12756
[mmmu]: https://arxiv.org/abs/2311.16502
[textvqa]: https://textvqa.org/
[realworldqa]: https://paperswithcode.com/dataset/realworldqa
[remi]: https://arxiv.org/html/2406.09175v1
[ai2d]: https://allenai.org/data/diagrams
[chartqa]: https://arxiv.org/abs/2203.10244
[vqav2]: https://visualqa.org/index.html
[blinkvqa]: https://arxiv.org/abs/2404.12390
[okvqa]: https://okvqa.allenai.org/
[tallyqa]: https://arxiv.org/abs/1810.12440
[ss-vqa]: https://arxiv.org/abs/1908.02660
[countbenchqa]: https://github.com/google-research/big_vision/blob/main/big_vision/datasets/countbenchqa/
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
- **Child Safety**: Evaluation of text-to-text and image to text prompts
covering child safety policies, including child sexual abuse and
exploitation.
- **Content Safety:** Evaluation of text-to-text and image to text prompts
covering safety policies including, harassment, violence and gore, and hate
speech.
- **Representational Harms**: Evaluation of text-to-text and image to text
prompts covering safety policies including bias, stereotyping, and harmful
associations or inaccuracies.
In addition to development level evaluations, we conduct "assurance
evaluations" which are our 'arms-length' internal evaluations for responsibility
governance decision making. They are conducted separately from the model
development team, to inform decision making about release. High level findings
are fed back to the model team, but prompt sets are held-out to prevent
overfitting and preserve the results' ability to inform decision making.
Assurance evaluation results are reported to our Responsibility & Safety Council
as part of release review.
### Evaluation Results
For all areas of safety testing, we saw major improvements in the categories of
child safety, content safety, and representational harms relative to previous
Gemma models. All testing was conducted without safety filters to evaluate the
model capabilities and behaviors. For both text-to-text and image-to-text, and
across all model sizes, the model produced minimal policy violations, and showed
significant improvements over previous Gemma models' performance with respect
to ungrounded inferences. A limitation of our evaluations was they included only
English language prompts.
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open vision-language models (VLMs) models have a wide range of applications
across various industries and domains. The following list of potential uses is
not comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
- Content Creation and Communication
- Text Generation: These models can be used to generate creative text
formats such as poems, scripts, code, marketing copy, and email drafts.
- Chatbots and Conversational AI: Power conversational interfaces
for customer service, virtual assistants, or interactive applications.
- Text Summarization: Generate concise summaries of a text corpus,
research papers, or reports.
- Image Data Extraction: These models can be used to extract,
interpret, and summarize visual data for text communications.
- Research and Education
- Natural Language Processing (NLP) and VLM Research: These
models can serve as a foundation for researchers to experiment with VLM
and NLP techniques, develop algorithms, and contribute to the
advancement of the field.
- Language Learning Tools: Support interactive language learning
experiences, aiding in grammar correction or providing writing practice.
- Knowledge Exploration: Assist researchers in exploring large
bodies of text by generating summaries or answering questions about
specific topics.
### Limitations
- Training Data
- The quality and diversity of the training data significantly
influence the model's capabilities. Biases or gaps in the training data
can lead to limitations in the model's responses.
- The scope of the training dataset determines the subject areas
the model can handle effectively.
- Context and Task Complexity
- Models are better at tasks that can be framed with clear
prompts and instructions. Open-ended or highly complex tasks might be
challenging.
- A model's performance can be influenced by the amount of context
provided (longer context generally leads to better outputs, up to a
certain point).
- Language Ambiguity and Nuance
- Natural language is inherently complex. Models might struggle
to grasp subtle nuances, sarcasm, or figurative language.
- Factual Accuracy
- Models generate responses based on information they learned
from their training datasets, but they are not knowledge bases. They
may generate incorrect or outdated factual statements.
- Common Sense
- Models rely on statistical patterns in language. They might
lack the ability to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of vision-language models (VLMs) raises several ethical
concerns. In creating an open model, we have carefully considered the following:
- Bias and Fairness
- VLMs trained on large-scale, real-world text and image data can
reflect socio-cultural biases embedded in the training material. These
models underwent careful scrutiny, input data pre-processing described
and posterior evaluations reported in this card.
- Misinformation and Misuse
- VLMs can be misused to generate text that is false, misleading,
or harmful.
- Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit][rai-toolkit].
- Transparency and Accountability:
- This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
- A responsibly developed open model offers the opportunity to
share innovation by making VLM technology accessible to developers and
researchers across the AI ecosystem.
Risks identified and mitigations:
- **Perpetuation of biases**: It's encouraged to perform continuous
monitoring (using evaluation metrics, human review) and the exploration of
de-biasing techniques during model training, fine-tuning, and other use
cases.
- **Generation of harmful content**: Mechanisms and guidelines for content
safety are essential. Developers are encouraged to exercise caution and
implement appropriate content safety safeguards based on their specific
product policies and application use cases.
- **Misuse for malicious purposes**: Technical limitations and developer
and end-user education can help mitigate against malicious applications of
VLMs. Educational resources and reporting mechanisms for users to flag
misuse are provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy][prohibited-use].
- **Privacy violations**: Models were trained on data filtered for removal
of certain personal information and other sensitive data. Developers are
encouraged to adhere to privacy regulations with privacy-preserving
techniques.
### Benefits
At the time of release, this family of models provides high-performance open
vision-language model implementations designed from the ground up for
responsible AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
[g3-tech-report]: https://goo.gle/Gemma3Report
[rai-toolkit]: https://ai.google.dev/responsible
[kaggle-gemma]: https://www.kaggle.com/models/google/gemma-3
[vertex-mg-gemma3]: https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3
[terms]: https://ai.google.dev/gemma/terms
[safety-policies]: https://ai.google/static/documents/ai-responsibility-update-published-february-2025.pdf
[prohibited-use]: https://ai.google.dev/gemma/prohibited_use_policy
[tpu]: https://cloud.google.com/tpu/docs/intro-to-tpu
[sustainability]: https://sustainability.google/operating-sustainably/
[jax]: https://github.com/jax-ml/jax
[ml-pathways]: https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[sustainability]: https://sustainability.google/operating-sustainably/
[gemini-2-paper]: https://arxiv.org/abs/2312.11805 |
ustc-community/dfine-large-coco | ustc-community | "2025-05-05T11:35:56Z" | 68 | 0 | transformers | [
"transformers",
"safetensors",
"d_fine",
"object-detection",
"vision",
"en",
"dataset:coco",
"arxiv:2410.13842",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | "2025-02-22T12:04:35Z" | ---
library_name: transformers
license: apache-2.0
language:
- en
pipeline_tag: object-detection
tags:
- object-detection
- vision
datasets:
- coco
---
## D-FINE
### **Overview**
The D-FINE model was proposed in [D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement](https://arxiv.org/abs/2410.13842) by
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, Feng Wu
This model was contributed by [VladOS95-cyber](https://github.com/VladOS95-cyber) with the help of [@qubvel-hf](https://huggingface.co/qubvel-hf)
This is the HF transformers implementation for D-FINE
_coco -> model trained on COCO
_obj365 -> model trained on Object365
_obj2coco -> model trained on Object365 and then finetuned on COCO
### **Performance**
D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD).

### **How to use**
```python
import torch
import requests
from PIL import Image
from transformers import DFineForObjectDetection, AutoImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("ustc-community/dfine-large-coco")
model = DFineForObjectDetection.from_pretrained("ustc-community/dfine-large-coco")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
```
### **Training**
D-FINE is trained on COCO (Lin et al. [2014]) train2017 and validated on COCO val2017 dataset. We report the standard AP metrics (averaged over uniformly sampled IoU thresholds ranging from 0.50 − 0.95 with a step size of 0.05), and APval5000 commonly used in real scenarios.
### **Applications**
D-FINE is ideal for real-time object detection in diverse applications such as **autonomous driving**, **surveillance systems**, **robotics**, and **retail analytics**. Its enhanced flexibility and deployment-friendly design make it suitable for both edge devices and large-scale systems + ensures high accuracy and speed in dynamic, real-world environments. |
Sim4Rec/inter-play-sim-assistant-sft | Sim4Rec | "2025-05-05T11:24:44Z" | 12 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-02-02T00:05:41Z" | ---
base_model: meta-llama/Llama-3.1-8B
library_name: transformers
model_name: inter-play-sim-assistant-sft
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for inter-play-sim-assistant-sft
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Sim4Rec/inter-play-sim-assistant-sft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jerome-ramos-20/huggingface/runs/lzvwgcqb)
This model was trained with SFT.
### Framework versions
- TRL: 0.14.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.0.1
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF | Triangle104 | "2025-05-05T10:59:32Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"nvidia",
"math",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:nvidia/OpenMathReasoning",
"base_model:nvidia/OpenMath-Nemotron-7B",
"base_model:quantized:nvidia/OpenMath-Nemotron-7B",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-05-05T10:57:22Z" | ---
base_model: nvidia/OpenMath-Nemotron-7B
datasets:
- nvidia/OpenMathReasoning
language:
- en
library_name: transformers
license: cc-by-4.0
tags:
- nvidia
- math
- llama-cpp
- gguf-my-repo
---
# Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF
This model was converted to GGUF format from [`nvidia/OpenMath-Nemotron-7B`](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) for more details on the model.
---
OpenMath-Nemotron-7B is created by finetuning Qwen/Qwen2.5-Math-7B on OpenMathReasoning dataset.
This model is ready for commercial use.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF --hf-file openmath-nemotron-7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF --hf-file openmath-nemotron-7b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF --hf-file openmath-nemotron-7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/OpenMath-Nemotron-7B-Q4_K_M-GGUF --hf-file openmath-nemotron-7b-q4_k_m.gguf -c 2048
```
|
mlgawd/cyberrealistic_pony | mlgawd | "2025-05-05T10:57:23Z" | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2025-05-05T10:55:33Z" | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MrRobotoAI/114-Q4_K_M-GGUF | MrRobotoAI | "2025-05-05T10:43:27Z" | 41 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:MrRobotoAI/114",
"base_model:quantized:MrRobotoAI/114",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-05-05T10:43:06Z" | ---
base_model: MrRobotoAI/114
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# MrRobotoAI/114-Q4_K_M-GGUF
This model was converted to GGUF format from [`MrRobotoAI/114`](https://huggingface.co/MrRobotoAI/114) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/MrRobotoAI/114) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo MrRobotoAI/114-Q4_K_M-GGUF --hf-file 114-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo MrRobotoAI/114-Q4_K_M-GGUF --hf-file 114-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo MrRobotoAI/114-Q4_K_M-GGUF --hf-file 114-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo MrRobotoAI/114-Q4_K_M-GGUF --hf-file 114-q4_k_m.gguf -c 2048
```
|
tori29umai/FramePackI2V_HY_rotate_indoor_F1 | tori29umai | "2025-05-05T10:03:44Z" | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"license:other",
"region:us"
] | null | "2025-05-05T09:53:58Z" | ---
license: other
license_name: other
license_link: https://huggingface.co/lllyasviel/FramePack_F1_I2V_HY_20250503
---
|
jssky/61de34b2-2cbe-474f-9759-7579b3f05a6a | jssky | "2025-05-05T09:56:11Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"axolotl",
"generated_from_trainer",
"conversational",
"base_model:NousResearch/Llama-2-7b-hf",
"base_model:finetune:NousResearch/Llama-2-7b-hf",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-05-05T09:40:09Z" | ---
library_name: transformers
base_model: NousResearch/Llama-2-7b-hf
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 61de34b2-2cbe-474f-9759-7579b3f05a6a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.9.0`
```yaml
base_model: NousResearch/Llama-2-7b-hf
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 012ab4813cc99fb8_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/012ab4813cc99fb8_train_data.json
type:
field_input: evidence
field_instruction: question
field_output: SQL
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: jssky/61de34b2-2cbe-474f-9759-7579b3f05a6a
hub_repo: null
hub_strategy: checkpoint
hub_token: null
huggingface_repo_visibility: public
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 10
lr_scheduler: cosine
max_steps: 1000
micro_batch_size: 2
mlflow_experiment_name: /tmp/012ab4813cc99fb8_train_data.json
num_epochs: 3
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 512
strict: false
tf32: false
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: b1e23278-252e-44d7-9491-1b28d344421c
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: b1e23278-252e-44d7-9491-1b28d344421c
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 61de34b2-2cbe-474f-9759-7579b3f05a6a
This model is a fine-tuned version of [NousResearch/Llama-2-7b-hf](https://huggingface.co/NousResearch/Llama-2-7b-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 594
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0051 | 1 | 1.0069 |
| 0.8986 | 0.2525 | 50 | 0.9070 |
| 0.732 | 0.5051 | 100 | 0.7708 |
| 0.6974 | 0.7576 | 150 | 0.7275 |
| 0.6078 | 1.0101 | 200 | 0.6594 |
| 0.401 | 1.2626 | 250 | 0.5793 |
| 0.3573 | 1.5152 | 300 | 0.5292 |
| 0.2894 | 1.7677 | 350 | 0.4295 |
| 0.2011 | 2.0202 | 400 | 0.3899 |
| 0.1267 | 2.2727 | 450 | 0.3806 |
| 0.1095 | 2.5253 | 500 | 0.3797 |
| 0.1124 | 2.7778 | 550 | 0.3758 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
hf-100/Mistral-Large-Instruct-2411-Spellbound-StoryWriter-123B-instruct-0.1-instruct-chkpt-80-adapter | hf-100 | "2025-05-05T09:50:46Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T09:33:36Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mcity-data-engine/fisheye8k_embedding_detection_transformer_torch | mcity-data-engine | "2025-05-05T09:11:01Z" | 0 | 0 | null | [
"dataset:Voxel51/fisheye8k",
"arxiv:2504.21614",
"region:us"
] | null | "2025-02-10T22:44:10Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
aparajitha11/hand-gcn-word | aparajitha11 | "2025-05-05T09:09:25Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T09:09:20Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
ghaniashafiqa/FT-Deepseek-7b-Adapter | ghaniashafiqa | "2025-05-05T09:06:16Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-05-05T09:05:57Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Don042/Test-run | Don042 | "2025-05-05T09:01:27Z" | 0 | 0 | null | [
"license:openrail",
"region:us"
] | null | "2025-05-05T09:01:17Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
bevinv/results | bevinv | "2025-05-05T08:54:23Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T08:54:20Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
baby-dev/4e9ed59d-cee2-42f9-b637-f3bcc0abc082 | baby-dev | "2025-05-05T08:51:36Z" | 0 | 0 | peft | [
"peft",
"generated_from_trainer",
"base_model:unsloth/codegemma-7b",
"base_model:adapter:unsloth/codegemma-7b",
"region:us"
] | null | "2025-05-05T08:51:09Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
RichardErkhov/hemanth955_-_Legal-Mistral-gguf | RichardErkhov | "2025-05-05T08:43:38Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T08:43:38Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Ideapad/qa_entropy_all_1e-05_full_5_forget10_layer-15-before_linear | Ideapad | "2025-05-05T08:43:32Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T08:43:32Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
karanpar/loraproject | karanpar | "2025-05-05T08:43:07Z" | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | "2025-05-05T08:43:07Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
DPO-RM/Qwen2.5-Math-1.5B-prime-no_logSoftmax-eurus_rl_15k-step120-reward | DPO-RM | "2025-05-05T08:42:13Z" | 0 | 0 | null | [
"safetensors",
"qwen2",
"region:us"
] | null | "2025-05-05T08:40:51Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
risolmayo/0446cd97-6f35-44df-bb7f-c6f9c3a956dd | risolmayo | "2025-05-05T08:42:09Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T08:33:22Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
prakanda/Audio_Features_BiLSTM | prakanda | "2025-05-05T08:33:16Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-02-06T12:45:30Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
DPO-RM/Qwen2.5-Math-1.5B-prime-no_logSoftmax-eurus_rl_15k-step90-actor | DPO-RM | "2025-05-05T08:28:07Z" | 0 | 0 | null | [
"safetensors",
"qwen2",
"region:us"
] | null | "2025-05-05T08:26:52Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
DPO-RM/Qwen2.5-Math-1.5B-prime-no_logSoftmax-eurus_rl_15k-step80-actor | DPO-RM | "2025-05-05T08:23:58Z" | 0 | 0 | null | [
"safetensors",
"qwen2",
"region:us"
] | null | "2025-05-05T08:22:41Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
DPO-RM/Qwen2.5-Math-1.5B-prime-no_logSoftmax-eurus_rl_15k-step70-reward | DPO-RM | "2025-05-05T08:21:17Z" | 0 | 0 | null | [
"safetensors",
"qwen2",
"region:us"
] | null | "2025-05-05T08:20:06Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
insidious316/llama-test | insidious316 | "2025-05-05T08:00:14Z" | 0 | 0 | null | [
"safetensors",
"llama",
"region:us"
] | null | "2025-05-05T07:11:42Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Minasanjotaro/270180c0-57a1-4947-9545-c96aa4b77dc2 | Minasanjotaro | "2025-05-05T08:00:08Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T07:24:04Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
albertus-sussex/veriscrape-fixed-simcse-auto-reference_2_to_verify_8-fold-7 | albertus-sussex | "2025-05-05T07:53:29Z" | 11 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2025-04-01T12:31:24Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
lesso02/a5fc37b5-9676-49df-b8a9-d95f8d8c081b | lesso02 | "2025-05-05T07:46:22Z" | 0 | 0 | null | [
"region:us"
] | null | "2025-05-05T07:00:04Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:website@huggingface.co">an email</a></p>
</div>
</main>
</body>
</html> |
Subsets and Splits