
AMD-HybridLM-Models
Collection
AMD-HybridLM is a family of post-trained, highly efficient hybrid models, designed to combine performance with speed and memory efficiency.
•
23 items
•
Updated
•
3
Zebra-Llama is a family of hybrid large language models (LLMs) proposed by AMD that composes Multi-head Latent Attention (MLA) and Mamba2 for KV cache compression and computational efficiency. Thus combination achieves Transformer-level accuracy with near-State Space Model (SSM) efficiency. While standard Transformers are limited by the quadratic complexity of self-attention and the large memory footprint of their key-value (KV) cache, Zebra-Llama offers a practical and scalable solution.
This model, Zebra-Llama-3B-14MLA-14Mamba-SFT, is created by efficiently adapting the pre-trained Llama-3.2-3B-Instruct model conducted post-training on AMD Instinct™ MI300X GPUs. This training approach bypasses the need for costly pre-training from scratch.
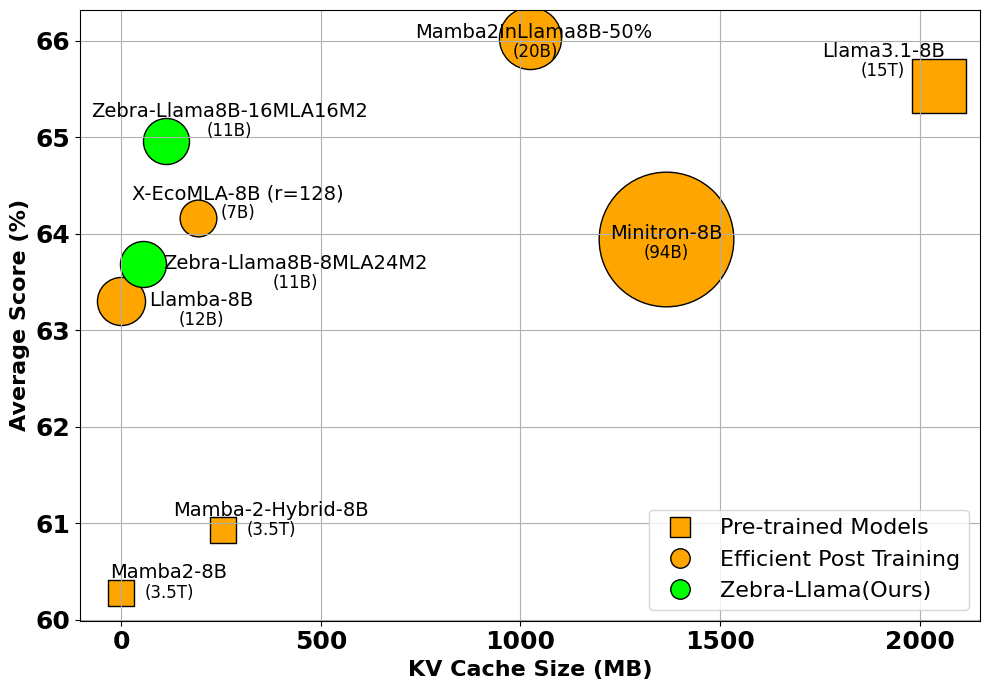 Figure 1: Comparing 8B-scale models on average LM Harness score vs. KV cache size. Zebra-Llama (green) matches or exceeds baselines with smaller KV cache and fewer training tokens. Circle and square sizes indicate training tokens (billions for post-training, trillions for pre-training).
Figure 1: Comparing 8B-scale models on average LM Harness score vs. KV cache size. Zebra-Llama (green) matches or exceeds baselines with smaller KV cache and fewer training tokens. Circle and square sizes indicate training tokens (billions for post-training, trillions for pre-training).
The Zebra-Llama models are not trained from scratch. Instead, they are composed from powerful pre-trained Transformers through a lightweight and efficient pipeline. The creation of this model followed these stages:
| Stage | Action | Description |
|---|---|---|
| 1. Base Model | Llama-3.2-3B-Instruct | The starting point is a high-quality, pre-trained Transformer model. |
| 2. Initialization | Structured Weight Mapping | Pure Mamba2 and MLA models are initialized from the base model's weights using structured mapping techniques (SVD for MLA, reinterpretation for Mamba2). |
| 3. Refinement | Intermediate Layer Distillation (ILD) | The internal representations of the Mamba2 and MLA models are aligned with the base model's layers on a small dataset to ensure a strong starting point. |
| 4. Composition | SMART Layer Selection | A hybrid architecture is composed using the SMART (Sensitivity Measure-Aware Replacement of Transformer layers) strategy to optimally place each layer type. |
| 5. SFT | End-to-End Knowledge Distillation | The composed hybrid model is fine-tuned via knowledge distillation, using an 8B model as a teacher to transfer rich, pre-trained knowledge. |
| 6. Alignment | Direct Preference Optimization (DPO) | In the final stage, DPO is used to align the model's preferences, with the distilled student model itself serving as the reference model for stability. |
| Stage | Dataset | License |
|---|---|---|
| ILD/SFT | https://huggingface.co/datasets/teknium/OpenHermes-2.5 | Refer source materials |
| ILD/SFT | https://huggingface.co/datasets/tomg-group-umd/GenQA | CC BY-NC 4.0 |
| ILD/SFT | https://huggingface.co/datasets/BAAI/Infinity-Instruct | CC BY-SA 4.0 |
| DPO | https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized | MIT |
| DPO | https://huggingface.co/datasets/HuggingFaceH4/orca_dpo_pairs | MIT |
| DPO | https://huggingface.co/datasets/JunxiongWang/llama3-ultrafeedback-armorm | MIT |
git clone https://github.com/AMD-AIG-AIMA/AMD-Hybrid-Models.git
Then follow the installation instruction in AMD-AIG-AIMA/AMD-Hybrid-Models repo.
Once the installation completed, we can try the following code for a quick test
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from hybrid.hybrid_wrapper import HybridModelWrapper
checkpoint = "amd/Zebra-Llama-3B-14MLA-14Mamba-SFT"
model = HybridModelWrapper.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).cuda()
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model.eval()
# Format the prompt using the chat template
prompt = [{"role": "user", "content": "What are the benefits of hybrid language models?"}]
input_ids = tokenizer.apply_chat_template(
prompt,
add_generation_prompt=True,
return_tensors='pt'
).cuda()
# Generate a response
tokens = model.generate(
input_ids,
max_new_tokens=256,
temperature=0.7,
do_sample=True,
eos_token_id=tokenizer.eos_token_id
)
print(tokenizer.decode(tokens[0], skip_special_tokens=False))
| Model | KV Size | Param | Index of MLA layers | rkv | rq | drope | dnope |
|---|---|---|---|---|---|---|---|
| Llama-3.2-3B-Instruct | 100% | 3.21B | - | - | - | - | - |
| Zebra-Llama-3B-6MLA-22Mamba | 2.01% | 3.39B | [0,5,10,16,21,26] | 128 | 1536 | 64 | 64 |
| Zebra-Llama-3B-14MLA-14Mamba | 4.69% | 3.27B | [0,2,4,6,8,10,12,14,16,18,20,22,24,26] | 128 | 1536 | 64 | 64 |
Zebra-Llama was evaluated on the Language Model Harness benchmark for zero-shot tasks and compared against its base model and other post-training methods. The results demonstrate that Zebra-Llama provides a superior balance of performance and efficiency.
| Tasks | Metric | Llama-3.2-3B-Instruct | Zebra-Llama-3B-6MLA-22M2-SFT | Zebra-Llama-3B-6MLA-22M2-DPO | Zebra-Llama-3B-14MLA-14M2-SFT | Zebra-Llama-3B-14MLA-14M2-DPO |
|---|---|---|---|---|---|---|
| arc_challenge | acc | 0.4369±0.0145 | 0.4189±0.0144 | 0.4744±0.0146 | 0.4326±0.0145 | 0.4966±0.0146 |
| acc_norm | 0.459±0.0146 | 0.4539±0.0145 | 0.5077±0.0146 | 0.4667±0.0146 | 0.5128±0.0146 | |
| arc_easy | acc | 0.7428±0.009 | 0.7677±0.0087 | 0.7984±0.0082 | 0.771±0.0086 | 0.7959±0.0083 |
| acc_norm | 0.6776±0.0096 | 0.7205±0.0092 | 0.7609±0.0088 | 0.7269±0.0091 | 0.7614±0.0087 | |
| hellaswag | acc | 0.5222±0.005 | 0.5014±0.005 | 0.5213±0.005 | 0.5068±0.005 | 0.531±0.005 |
| acc_norm | 0.7036±0.0046 | 0.6812±0.0047 | 0.7146±0.0045 | 0.6875±0.0046 | 0.7257±0.0045 | |
| mmlu | acc | 0.6046±0.1057 | 0.5049±0.103 | 0.5006±0.1038 | 0.528±0.1069 | 0.521±0.1057 |
| - humanities | acc | 0.5926±0.0826 | 0.4553±0.1006 | 0.4493±0.0948 | 0.4759±0.1027 | 0.4721±0.1008 |
| - other | acc | 0.6598±0.1118 | 0.5626±0.0935 | 0.5603±0.0971 | 0.5919±0.0948 | 0.5855±0.0916 |
| - social_sciences | acc | 0.6701±0.0712 | 0.5899±0.083 | 0.584±0.0871 | 0.6113±0.0848 | 0.6081±0.081 |
| - stem | acc | 0.5043±0.1122 | 0.4393±0.0894 | 0.437±0.0959 | 0.4615±0.1003 | 0.4456±0.0987 |
| openbookqa | acc | 0.274±0.02 | 0.278±0.0201 | 0.324±0.021 | 0.282±0.0201 | 0.33±0.021 |
| acc_norm | 0.362±0.0215 | 0.386±0.0218 | 0.434±0.0222 | 0.394±0.0219 | 0.424±0.0221 | |
| piqa | acc | 0.7606±0.01 | 0.753±0.0101 | 0.772±0.0098 | 0.7617±0.0099 | 0.7775±0.0097 |
| acc_norm | 0.7557±0.01 | 0.7573±0.01 | 0.7726±0.0098 | 0.7579±0.01 | 0.7753±0.0097 | |
| pubmedqa | acc | 0.696±0.0206 | 0.612±0.0218 | 0.62±0.0217 | 0.648±0.0214 | 0.63±0.0216 |
| race | acc | 0.4077±0.0152 | 0.3904±0.0151 | 0.4249±0.0153 | 0.4048±0.0152 | 0.4593±0.0154 |
| winogrande | acc | 0.6717±0.0132 | 0.6614±0.0133 | 0.6646±0.0133 | 0.6598±0.0133 | 0.6756±0.0132 |
Zebra-Llama demonstrates a practical and scalable framework for composing highly efficient hybrid models from existing pre-trained Transformers. By intelligently combining MLA and Mamba2 layers, this approach drastically reduces memory requirements and improves inference throughput while preserving the strong capabilities of the original model. This work highlights the viability of post-training hybridization as a cost-effective and environmentally sustainable alternative to full retraining, paving the way for the deployment of powerful LLMs in resource-constrained environments.
If you find this model useful, please consider citing the original paper:
@article{yang2025zebra,
title={Zebra-Llama: Towards Extremely Efficient Hybrid Models},
author={Yang, Mingyu and Rezagholizadeh, Mehdi and Li, Guihong and Appia, Vikram and Barsoum, Emad},
journal={arXiv preprint arXiv:2505.17272},
year={2025}
}
@article{li2025x,
title={X-ecomla: Upcycling pre-trained attention into mla for efficient and extreme kv compression},
author={Li, Guihong and Rezagholizadeh, Mehdi and Yang, Mingyu and Appia, Vikram and Barsoum, Emad},
journal={arXiv preprint arXiv:2503.11132},
year={2025}
}