Spaces:
Running

Running

Feedback and style changes
Browse filesSimplified style of Candid resource links. Added feedback tab.
- app.py +81 -9
- ask_candid/agents/schema.py +27 -0
- ask_candid/base/config/constants.py +4 -0
- ask_candid/chat.py +23 -216
- ask_candid/graph.py +177 -0
- ask_candid/retrieval/elastic.py +194 -23
- ask_candid/services/small_lm.py +2 -1
- ask_candid/tools/org_seach.py +55 -5
- ask_candid/tools/recommendation.py +189 -0
- ask_candid/tools/search.py +38 -0
- static/chatStyle.css +6 -5
- static/elastic_agent_worflow.jpeg +0 -0
app.py
CHANGED
|
@@ -4,7 +4,6 @@ import os
|
|
| 4 |
import gradio as gr
|
| 5 |
|
| 6 |
from langchain_core.language_models.llms import LLM
|
| 7 |
-
|
| 8 |
from langchain_openai.chat_models import ChatOpenAI
|
| 9 |
from langchain_aws import ChatBedrock
|
| 10 |
import boto3
|
|
@@ -15,9 +14,12 @@ from ask_candid.base.config.data import ALL_INDICES
|
|
| 15 |
from ask_candid.utils import format_chat_ag_response
|
| 16 |
from ask_candid.chat import run_chat
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
ROOT = os.path.dirname(os.path.abspath(__file__))
|
| 19 |
-
BUCKET = "candid-data-science-reporting"
|
| 20 |
-
PREFIX = "Assistant"
|
| 21 |
|
| 22 |
class LoggedComponents(TypedDict):
|
| 23 |
context: List[gr.components.Component]
|
|
@@ -27,6 +29,31 @@ class LoggedComponents(TypedDict):
|
|
| 27 |
email: gr.components.Component
|
| 28 |
|
| 29 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
def select_foundation_model(model_name: str, max_new_tokens: int) -> LLM:
|
| 31 |
if model_name == "gpt-4o":
|
| 32 |
llm = ChatOpenAI(
|
|
@@ -92,7 +119,7 @@ def build_rag_chat() -> Tuple[LoggedComponents, gr.Blocks]:
|
|
| 92 |
)
|
| 93 |
llmname = gr.Radio(
|
| 94 |
label="Language model",
|
| 95 |
-
value="
|
| 96 |
choices=list(Name2Endpoint.keys()),
|
| 97 |
interactive=True,
|
| 98 |
)
|
|
@@ -118,8 +145,8 @@ def build_rag_chat() -> Tuple[LoggedComponents, gr.Blocks]:
|
|
| 118 |
type="messages",
|
| 119 |
show_label=False,
|
| 120 |
show_copy_button=True,
|
| 121 |
-
show_share_button=
|
| 122 |
-
show_copy_all_button=
|
| 123 |
)
|
| 124 |
msg = gr.MultimodalTextbox(label="Your message", interactive=True)
|
| 125 |
thread_id = gr.Text(visible=False, value="", label="thread_id")
|
|
@@ -132,12 +159,54 @@ def build_rag_chat() -> Tuple[LoggedComponents, gr.Blocks]:
|
|
| 132 |
outputs=[msg, chatbot, thread_id],
|
| 133 |
)
|
| 134 |
chat_msg.then(format_chat_ag_response, chatbot, chatbot, api_name="bot_response")
|
| 135 |
-
logged = LoggedComponents(context=
|
| 136 |
return logged, demo
|
| 137 |
|
| 138 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
def build_app():
|
| 140 |
-
|
|
|
|
| 141 |
|
| 142 |
with open(os.path.join(ROOT, "static", "chatStyle.css"), "r", encoding="utf8") as f:
|
| 143 |
css_chat = f.read()
|
|
@@ -145,10 +214,13 @@ def build_app():
|
|
| 145 |
demo = gr.TabbedInterface(
|
| 146 |
interface_list=[
|
| 147 |
candid_chat,
|
|
|
|
| 148 |
],
|
| 149 |
tab_names=[
|
| 150 |
-
"
|
|
|
|
| 151 |
],
|
|
|
|
| 152 |
theme=gr.themes.Soft(),
|
| 153 |
css=css_chat,
|
| 154 |
)
|
|
|
|
| 4 |
import gradio as gr
|
| 5 |
|
| 6 |
from langchain_core.language_models.llms import LLM
|
|
|
|
| 7 |
from langchain_openai.chat_models import ChatOpenAI
|
| 8 |
from langchain_aws import ChatBedrock
|
| 9 |
import boto3
|
|
|
|
| 14 |
from ask_candid.utils import format_chat_ag_response
|
| 15 |
from ask_candid.chat import run_chat
|
| 16 |
|
| 17 |
+
try:
|
| 18 |
+
from feedback import FeedbackApi
|
| 19 |
+
except ImportError:
|
| 20 |
+
from demos.feedback import FeedbackApi
|
| 21 |
+
|
| 22 |
ROOT = os.path.dirname(os.path.abspath(__file__))
|
|
|
|
|
|
|
| 23 |
|
| 24 |
class LoggedComponents(TypedDict):
|
| 25 |
context: List[gr.components.Component]
|
|
|
|
| 29 |
email: gr.components.Component
|
| 30 |
|
| 31 |
|
| 32 |
+
def send_feedback(
|
| 33 |
+
chat_context,
|
| 34 |
+
found_helpful,
|
| 35 |
+
will_recommend,
|
| 36 |
+
comments,
|
| 37 |
+
email
|
| 38 |
+
):
|
| 39 |
+
api = FeedbackApi()
|
| 40 |
+
total_submissions = 0
|
| 41 |
+
|
| 42 |
+
try:
|
| 43 |
+
response = api(
|
| 44 |
+
context=chat_context,
|
| 45 |
+
found_helpful=found_helpful,
|
| 46 |
+
will_recommend=will_recommend,
|
| 47 |
+
comments=comments,
|
| 48 |
+
email=email
|
| 49 |
+
)
|
| 50 |
+
total_submissions = response.get("response", 0)
|
| 51 |
+
gr.Info("Thank you for submitting feedback")
|
| 52 |
+
except Exception as ex:
|
| 53 |
+
raise gr.Error(f"Error submitting feedback: {ex}")
|
| 54 |
+
return total_submissions
|
| 55 |
+
|
| 56 |
+
|
| 57 |
def select_foundation_model(model_name: str, max_new_tokens: int) -> LLM:
|
| 58 |
if model_name == "gpt-4o":
|
| 59 |
llm = ChatOpenAI(
|
|
|
|
| 119 |
)
|
| 120 |
llmname = gr.Radio(
|
| 121 |
label="Language model",
|
| 122 |
+
value="claude-3.5-haiku",
|
| 123 |
choices=list(Name2Endpoint.keys()),
|
| 124 |
interactive=True,
|
| 125 |
)
|
|
|
|
| 145 |
type="messages",
|
| 146 |
show_label=False,
|
| 147 |
show_copy_button=True,
|
| 148 |
+
show_share_button=None,
|
| 149 |
+
show_copy_all_button=False,
|
| 150 |
)
|
| 151 |
msg = gr.MultimodalTextbox(label="Your message", interactive=True)
|
| 152 |
thread_id = gr.Text(visible=False, value="", label="thread_id")
|
|
|
|
| 159 |
outputs=[msg, chatbot, thread_id],
|
| 160 |
)
|
| 161 |
chat_msg.then(format_chat_ag_response, chatbot, chatbot, api_name="bot_response")
|
| 162 |
+
logged = LoggedComponents(context=chatbot)
|
| 163 |
return logged, demo
|
| 164 |
|
| 165 |
|
| 166 |
+
def build_feedback(components: LoggedComponents) -> gr.Blocks:
|
| 167 |
+
with gr.Blocks(theme=gr.themes.Soft(), title="Candid AI demo") as demo:
|
| 168 |
+
gr.Markdown("<h1>Help us improve this tool with your valuable feedback</h1>")
|
| 169 |
+
|
| 170 |
+
with gr.Row():
|
| 171 |
+
with gr.Column():
|
| 172 |
+
found_helpful = gr.Radio(
|
| 173 |
+
[True, False], label="Did you find what you were looking for?"
|
| 174 |
+
)
|
| 175 |
+
will_recommend = gr.Radio(
|
| 176 |
+
[True, False],
|
| 177 |
+
label="Will you recommend this Chatbot to others?",
|
| 178 |
+
)
|
| 179 |
+
comment = gr.Textbox(label="Additional comments (optional)", lines=4)
|
| 180 |
+
email = gr.Textbox(label="Your email (optional)", lines=1)
|
| 181 |
+
submit = gr.Button("Submit Feedback")
|
| 182 |
+
|
| 183 |
+
components["found_helpful"] = found_helpful
|
| 184 |
+
components["will_recommend"] = will_recommend
|
| 185 |
+
components["comments"] = comment
|
| 186 |
+
components["email"] = email
|
| 187 |
+
|
| 188 |
+
# pylint: disable=no-member
|
| 189 |
+
submit.click(
|
| 190 |
+
fn=send_feedback,
|
| 191 |
+
inputs=[
|
| 192 |
+
components["context"],
|
| 193 |
+
components["found_helpful"],
|
| 194 |
+
components["will_recommend"],
|
| 195 |
+
components["comments"],
|
| 196 |
+
components["email"]
|
| 197 |
+
],
|
| 198 |
+
outputs=None,
|
| 199 |
+
show_api=False,
|
| 200 |
+
api_name=False,
|
| 201 |
+
preprocess=False,
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
return demo
|
| 205 |
+
|
| 206 |
+
|
| 207 |
def build_app():
|
| 208 |
+
logger, candid_chat = build_rag_chat()
|
| 209 |
+
feedback = build_feedback(logger)
|
| 210 |
|
| 211 |
with open(os.path.join(ROOT, "static", "chatStyle.css"), "r", encoding="utf8") as f:
|
| 212 |
css_chat = f.read()
|
|
|
|
| 214 |
demo = gr.TabbedInterface(
|
| 215 |
interface_list=[
|
| 216 |
candid_chat,
|
| 217 |
+
feedback
|
| 218 |
],
|
| 219 |
tab_names=[
|
| 220 |
+
"Ask Candid",
|
| 221 |
+
"Feedback"
|
| 222 |
],
|
| 223 |
+
title="Ask Candid Assistant",
|
| 224 |
theme=gr.themes.Soft(),
|
| 225 |
css=css_chat,
|
| 226 |
)
|
ask_candid/agents/schema.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Dict, TypedDict, Sequence, Union, Annotated
|
| 2 |
+
|
| 3 |
+
from langchain_core.messages import BaseMessage
|
| 4 |
+
from langgraph.graph.message import add_messages
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Context(TypedDict):
|
| 8 |
+
"""PCS + geonames context payload for common tasks like recommendations.
|
| 9 |
+
"""
|
| 10 |
+
subject: List[str]
|
| 11 |
+
population: List[str]
|
| 12 |
+
geography: List[Union[str, int]]
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class AgentState(TypedDict):
|
| 16 |
+
"""State of the chat agent for the execution graph(s).
|
| 17 |
+
"""
|
| 18 |
+
# The add_messages function defines how an update should be processed
|
| 19 |
+
# Default is to replace. add_messages says "append"
|
| 20 |
+
messages: Annotated[Sequence[BaseMessage], add_messages]
|
| 21 |
+
user_input: str
|
| 22 |
+
org_dict: Dict
|
| 23 |
+
|
| 24 |
+
# Recommendation-specific fields
|
| 25 |
+
intent: str
|
| 26 |
+
context: Context
|
| 27 |
+
recommendation: str
|
ask_candid/base/config/constants.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
START_SYSTEM_PROMPT = (
|
| 2 |
+
"You are a Candid subject matter expert on the social sector and philanthropy. "
|
| 3 |
+
"You should address the user's queries and stay on topic."
|
| 4 |
+
)
|
ask_candid/chat.py
CHANGED
|
@@ -1,204 +1,12 @@
|
|
| 1 |
-
from typing import List,
|
| 2 |
-
from functools import partial
|
| 3 |
-
import logging
|
| 4 |
-
import os
|
| 5 |
|
| 6 |
import gradio as gr
|
| 7 |
-
|
| 8 |
-
from langchain_core.messages import AIMessage, BaseMessage
|
| 9 |
-
from langchain_core.output_parsers import StrOutputParser
|
| 10 |
-
from langchain_core.prompts import ChatPromptTemplate
|
| 11 |
from langchain_core.language_models.llms import LLM
|
| 12 |
-
|
| 13 |
-
from langgraph.prebuilt import tools_condition, ToolNode
|
| 14 |
from langgraph.checkpoint.memory import MemorySaver
|
| 15 |
-
from langgraph.graph.state import StateGraph
|
| 16 |
-
from langgraph.graph.message import add_messages
|
| 17 |
-
from langgraph.constants import START, END
|
| 18 |
-
|
| 19 |
-
from ask_candid.tools.org_seach import extract_org_links_from_chatbot, embed_org_links_in_text, generate_org_link_dict
|
| 20 |
-
from ask_candid.tools.question_reformulation import reformulate_question_using_history
|
| 21 |
-
from ask_candid.utils import html_format_docs_chat, get_session_id
|
| 22 |
-
from ask_candid.retrieval.elastic import retriever_tool
|
| 23 |
-
|
| 24 |
-
ROOT = os.path.dirname(os.path.abspath(__file__))
|
| 25 |
-
logging.basicConfig(format="[%(levelname)s] (%(asctime)s) :: %(message)s")
|
| 26 |
-
logger = logging.getLogger(__name__)
|
| 27 |
-
logger.setLevel(logging.INFO)
|
| 28 |
-
|
| 29 |
-
# TODO https://www.metadocs.co/2024/08/29/simple-domain-specific-corrective-rag-with-langchain-and-langgraph/
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
class AgentState(TypedDict):
|
| 33 |
-
# The add_messages function defines how an update should be processed
|
| 34 |
-
# Default is to replace. add_messages says "append"
|
| 35 |
-
messages: Annotated[Sequence[BaseMessage], add_messages]
|
| 36 |
-
user_input: str
|
| 37 |
-
org_dict: Dict
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
def search_agent(state, llm: LLM, tools) -> AgentState:
|
| 41 |
-
"""Invokes the agent model to generate a response based on the current state. Given
|
| 42 |
-
the question, it will decide to retrieve using the retriever tool, or simply end.
|
| 43 |
-
|
| 44 |
-
Parameters
|
| 45 |
-
----------
|
| 46 |
-
state : _type_
|
| 47 |
-
The current state
|
| 48 |
-
llm : LLM
|
| 49 |
-
tools : _type_
|
| 50 |
-
_description_
|
| 51 |
-
|
| 52 |
-
Returns
|
| 53 |
-
-------
|
| 54 |
-
AgentState
|
| 55 |
-
The updated state with the agent response appended to messages
|
| 56 |
-
"""
|
| 57 |
-
|
| 58 |
-
logger.info("---SEARCH AGENT---")
|
| 59 |
-
messages = state["messages"]
|
| 60 |
-
question = messages[-1].content
|
| 61 |
-
|
| 62 |
-
model = llm.bind_tools(tools)
|
| 63 |
-
response = model.invoke(messages)
|
| 64 |
-
# return a list, because this will get added to the existing list
|
| 65 |
-
return {"messages": [response], "user_input": question}
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
def generate_with_context(state, llm: LLM) -> AgentState:
|
| 69 |
-
"""Generate answer.
|
| 70 |
-
|
| 71 |
-
Parameters
|
| 72 |
-
----------
|
| 73 |
-
state : _type_
|
| 74 |
-
The current state
|
| 75 |
-
llm : LLM
|
| 76 |
-
tools : _type_
|
| 77 |
-
_description_
|
| 78 |
-
|
| 79 |
-
Returns
|
| 80 |
-
-------
|
| 81 |
-
AgentState
|
| 82 |
-
The updated state with the agent response appended to messages
|
| 83 |
-
"""
|
| 84 |
-
|
| 85 |
-
logger.info("---GENERATE ANSWER---")
|
| 86 |
-
messages = state["messages"]
|
| 87 |
-
question = state["user_input"]
|
| 88 |
-
last_message = messages[-1]
|
| 89 |
-
|
| 90 |
-
sources_str = last_message.content
|
| 91 |
-
sources_list = last_message.artifact # cannot use directly as list of Documents
|
| 92 |
-
# converting to html string
|
| 93 |
-
sources_html = html_format_docs_chat(sources_list)
|
| 94 |
-
if sources_list:
|
| 95 |
-
logger.info("---ADD SOURCES---")
|
| 96 |
-
state["messages"].append(BaseMessage(content=sources_html, type="HTML"))
|
| 97 |
-
|
| 98 |
-
# Prompt
|
| 99 |
-
qa_system_prompt = """
|
| 100 |
-
You are an assistant for question-answering tasks in the social and philanthropic sector. \n
|
| 101 |
-
Use the following pieces of retrieved context to answer the question at the end. \n
|
| 102 |
-
If you don't know the answer, just say that you don't know. \n
|
| 103 |
-
Keep the response professional, friendly, and as concise as possible. \n
|
| 104 |
-
Question: {question}
|
| 105 |
-
Context: {context}
|
| 106 |
-
Answer:
|
| 107 |
-
"""
|
| 108 |
-
|
| 109 |
-
qa_prompt = ChatPromptTemplate(
|
| 110 |
-
[
|
| 111 |
-
("system", qa_system_prompt),
|
| 112 |
-
("human", question),
|
| 113 |
-
]
|
| 114 |
-
)
|
| 115 |
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
return {"messages": [AIMessage(content=response)], "user_input": question}
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
def has_org_name(state: AgentState) -> AgentState:
|
| 123 |
-
"""
|
| 124 |
-
Processes the latest message to extract organization links and determine the next step.
|
| 125 |
-
|
| 126 |
-
Args:
|
| 127 |
-
state (AgentState): The current state of the agent, including a list of messages.
|
| 128 |
-
|
| 129 |
-
Returns:
|
| 130 |
-
dict: A dictionary with the next agent action and, if available, a dictionary of organization links.
|
| 131 |
-
"""
|
| 132 |
-
logger.info("---HAS ORG NAMES?---")
|
| 133 |
-
messages = state["messages"]
|
| 134 |
-
last_message = messages[-1].content
|
| 135 |
-
output_list = extract_org_links_from_chatbot(last_message)
|
| 136 |
-
link_dict = generate_org_link_dict(output_list) if output_list else {}
|
| 137 |
-
if link_dict:
|
| 138 |
-
logger.info("---FOUND ORG NAMES---")
|
| 139 |
-
return {"next": "insert_org_link", "org_dict": link_dict}
|
| 140 |
-
logger.info("---NO ORG NAMES FOUND---")
|
| 141 |
-
return {"next": END, "messages": messages}
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
def insert_org_link(state: AgentState) -> AgentState:
|
| 145 |
-
"""
|
| 146 |
-
Embeds organization links in the latest message content and returns it as an AI message.
|
| 147 |
-
|
| 148 |
-
Args:
|
| 149 |
-
state (dict): The current state, including the organization links and latest message.
|
| 150 |
-
|
| 151 |
-
Returns:
|
| 152 |
-
dict: A dictionary with the updated message content as an AIMessage.
|
| 153 |
-
"""
|
| 154 |
-
logger.info("---INSERT ORG LINKS---")
|
| 155 |
-
messages = state["messages"]
|
| 156 |
-
last_message = messages[-1].content
|
| 157 |
-
messages.pop(-1) # Deleting the original message because we will append the same one but with links
|
| 158 |
-
link_dict = state["org_dict"]
|
| 159 |
-
last_message = embed_org_links_in_text(last_message, link_dict)
|
| 160 |
-
return {"messages": [AIMessage(content=last_message)]}
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
def build_compute_graph(llm: LLM, indices: List[str]) -> StateGraph:
|
| 164 |
-
candid_retriever_tool = retriever_tool(indices=indices)
|
| 165 |
-
retrieve = ToolNode([candid_retriever_tool])
|
| 166 |
-
tools = [candid_retriever_tool]
|
| 167 |
-
|
| 168 |
-
G = StateGraph(AgentState)
|
| 169 |
-
# Add nodes
|
| 170 |
-
G.add_node("reformulate", partial(reformulate_question_using_history, llm=llm))
|
| 171 |
-
G.add_node("search_agent", partial(search_agent, llm=llm, tools=tools))
|
| 172 |
-
G.add_node("retrieve", retrieve)
|
| 173 |
-
G.add_node("generate_with_context", partial(generate_with_context, llm=llm))
|
| 174 |
-
G.add_node("has_org_name", has_org_name)
|
| 175 |
-
G.add_node("insert_org_link", insert_org_link)
|
| 176 |
-
|
| 177 |
-
# Add edges
|
| 178 |
-
G.add_edge(START, "reformulate")
|
| 179 |
-
G.add_edge("reformulate", "search_agent")
|
| 180 |
-
# Conditional edges from search_agent
|
| 181 |
-
G.add_conditional_edges(
|
| 182 |
-
source="search_agent",
|
| 183 |
-
path=tools_condition,
|
| 184 |
-
path_map={
|
| 185 |
-
"tools": "retrieve",
|
| 186 |
-
END: "has_org_name",
|
| 187 |
-
},
|
| 188 |
-
)
|
| 189 |
-
G.add_edge("retrieve", "generate_with_context")
|
| 190 |
-
|
| 191 |
-
# Add edges
|
| 192 |
-
G.add_edge("generate_with_context", "has_org_name")
|
| 193 |
-
# Use add_conditional_edges for has_org_name
|
| 194 |
-
G.add_conditional_edges(
|
| 195 |
-
"has_org_name",
|
| 196 |
-
lambda x: x["next"], # Now we're accessing the 'next' key from the dict
|
| 197 |
-
{"insert_org_link": "insert_org_link", END: END},
|
| 198 |
-
)
|
| 199 |
-
G.add_edge("insert_org_link", END)
|
| 200 |
-
|
| 201 |
-
return G
|
| 202 |
|
| 203 |
|
| 204 |
def run_chat(
|
|
@@ -207,17 +15,10 @@ def run_chat(
|
|
| 207 |
history: List[Dict],
|
| 208 |
llm: LLM,
|
| 209 |
indices: Optional[List[str]] = None,
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
if len(history) == 0:
|
| 214 |
-
history.append({
|
| 215 |
-
"role": "system",
|
| 216 |
-
"content": (
|
| 217 |
-
"You are a Candid subject matter expert on the social sector and philanthropy. "
|
| 218 |
-
"You should address the user's queries and stay on topic."
|
| 219 |
-
)
|
| 220 |
-
})
|
| 221 |
|
| 222 |
history.append({"role": "user", "content": user_input["text"]})
|
| 223 |
inputs = {"messages": history}
|
|
@@ -225,14 +26,22 @@ def run_chat(
|
|
| 225 |
thread_id = get_session_id(thread_id)
|
| 226 |
config = {"configurable": {"thread_id": thread_id}}
|
| 227 |
|
| 228 |
-
workflow = build_compute_graph(llm=llm, indices=indices)
|
| 229 |
|
| 230 |
memory = MemorySaver() # TODO: don't use for Prod
|
| 231 |
graph = workflow.compile(checkpointer=memory)
|
| 232 |
response = graph.invoke(inputs, config=config)
|
| 233 |
messages = response["messages"]
|
| 234 |
-
|
| 235 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
sources_html = ""
|
| 237 |
for message in messages[-2:]:
|
| 238 |
if message.type == "HTML":
|
|
@@ -240,12 +49,10 @@ def run_chat(
|
|
| 240 |
|
| 241 |
history.append({"role": "assistant", "content": ai_answer})
|
| 242 |
if sources_html:
|
| 243 |
-
history.append(
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
}
|
| 249 |
-
)
|
| 250 |
|
| 251 |
return gr.MultimodalTextbox(value=None, interactive=True), history, thread_id
|
|
|
|
| 1 |
+
from typing import List, Dict, Tuple, Optional, Any
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
from langchain_core.language_models.llms import LLM
|
|
|
|
|
|
|
| 5 |
from langgraph.checkpoint.memory import MemorySaver
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
+
from ask_candid.utils import get_session_id
|
| 8 |
+
from ask_candid.graph import build_compute_graph
|
| 9 |
+
from ask_candid.base.config.constants import START_SYSTEM_PROMPT
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
|
| 12 |
def run_chat(
|
|
|
|
| 15 |
history: List[Dict],
|
| 16 |
llm: LLM,
|
| 17 |
indices: Optional[List[str]] = None,
|
| 18 |
+
enable_recommendations: bool = False
|
| 19 |
+
) -> Tuple[gr.MultimodalTextbox, List[Dict[str, Any]], str]:
|
|
|
|
| 20 |
if len(history) == 0:
|
| 21 |
+
history.append({"role": "system", "content": START_SYSTEM_PROMPT})
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
|
| 23 |
history.append({"role": "user", "content": user_input["text"]})
|
| 24 |
inputs = {"messages": history}
|
|
|
|
| 26 |
thread_id = get_session_id(thread_id)
|
| 27 |
config = {"configurable": {"thread_id": thread_id}}
|
| 28 |
|
| 29 |
+
workflow = build_compute_graph(llm=llm, indices=indices, enable_recommendations=enable_recommendations)
|
| 30 |
|
| 31 |
memory = MemorySaver() # TODO: don't use for Prod
|
| 32 |
graph = workflow.compile(checkpointer=memory)
|
| 33 |
response = graph.invoke(inputs, config=config)
|
| 34 |
messages = response["messages"]
|
| 35 |
+
|
| 36 |
+
# Return the recommendation if there is any
|
| 37 |
+
recommendation = response.get("recommendation", None)
|
| 38 |
+
if recommendation:
|
| 39 |
+
ai_answer = recommendation
|
| 40 |
+
else:
|
| 41 |
+
# Fallback to the chatbot response
|
| 42 |
+
last_message = messages[-1]
|
| 43 |
+
ai_answer = last_message.content
|
| 44 |
+
|
| 45 |
sources_html = ""
|
| 46 |
for message in messages[-2:]:
|
| 47 |
if message.type == "HTML":
|
|
|
|
| 49 |
|
| 50 |
history.append({"role": "assistant", "content": ai_answer})
|
| 51 |
if sources_html:
|
| 52 |
+
history.append({
|
| 53 |
+
"role": "assistant",
|
| 54 |
+
"content": sources_html,
|
| 55 |
+
"metadata": {"title": "Sources HTML"},
|
| 56 |
+
})
|
|
|
|
|
|
|
| 57 |
|
| 58 |
return gr.MultimodalTextbox(value=None, interactive=True), history, thread_id
|
ask_candid/graph.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from functools import partial
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
from langchain_core.messages import AIMessage, BaseMessage
|
| 6 |
+
from langchain_core.output_parsers import StrOutputParser
|
| 7 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 8 |
+
from langchain_core.language_models.llms import LLM
|
| 9 |
+
|
| 10 |
+
from langgraph.prebuilt import tools_condition, ToolNode
|
| 11 |
+
from langgraph.graph.state import StateGraph
|
| 12 |
+
from langgraph.constants import START, END
|
| 13 |
+
|
| 14 |
+
from ask_candid.retrieval.elastic import retriever_tool
|
| 15 |
+
from ask_candid.tools.recommendation import (
|
| 16 |
+
detect_intent_with_llm,
|
| 17 |
+
determine_context,
|
| 18 |
+
make_recommendation
|
| 19 |
+
)
|
| 20 |
+
from ask_candid.tools.question_reformulation import reformulate_question_using_history
|
| 21 |
+
from ask_candid.tools.org_seach import has_org_name, insert_org_link
|
| 22 |
+
from ask_candid.tools.search import search_agent
|
| 23 |
+
from ask_candid.agents.schema import AgentState
|
| 24 |
+
|
| 25 |
+
from ask_candid.utils import html_format_docs_chat
|
| 26 |
+
|
| 27 |
+
logging.basicConfig(format="[%(levelname)s] (%(asctime)s) :: %(message)s")
|
| 28 |
+
logger = logging.getLogger(__name__)
|
| 29 |
+
logger.setLevel(logging.INFO)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def generate_with_context(state: AgentState, llm: LLM) -> AgentState:
|
| 33 |
+
"""Generate answer.
|
| 34 |
+
|
| 35 |
+
Parameters
|
| 36 |
+
----------
|
| 37 |
+
state : AgentState
|
| 38 |
+
The current state
|
| 39 |
+
llm : LLM
|
| 40 |
+
|
| 41 |
+
Returns
|
| 42 |
+
-------
|
| 43 |
+
AgentState
|
| 44 |
+
The updated state with the agent response appended to messages
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
logger.info("---GENERATE ANSWER---")
|
| 48 |
+
messages = state["messages"]
|
| 49 |
+
question = state["user_input"]
|
| 50 |
+
last_message = messages[-1]
|
| 51 |
+
|
| 52 |
+
sources_str = last_message.content
|
| 53 |
+
sources_list = last_message.artifact # cannot use directly as list of Documents
|
| 54 |
+
# converting to html string
|
| 55 |
+
sources_html = html_format_docs_chat(sources_list)
|
| 56 |
+
if sources_list:
|
| 57 |
+
logger.info("---ADD SOURCES---")
|
| 58 |
+
state["messages"].append(BaseMessage(content=sources_html, type="HTML"))
|
| 59 |
+
|
| 60 |
+
# Prompt
|
| 61 |
+
qa_system_prompt = """
|
| 62 |
+
You are an assistant for question-answering tasks in the social and philanthropic sector. \n
|
| 63 |
+
Use the following pieces of retrieved context to answer the question at the end. \n
|
| 64 |
+
If you don't know the answer, just say that you don't know. \n
|
| 65 |
+
Keep the response professional, friendly, and as concise as possible. \n
|
| 66 |
+
Question: {question}
|
| 67 |
+
Context: {context}
|
| 68 |
+
Answer:
|
| 69 |
+
"""
|
| 70 |
+
|
| 71 |
+
qa_prompt = ChatPromptTemplate([
|
| 72 |
+
("system", qa_system_prompt),
|
| 73 |
+
("human", question),
|
| 74 |
+
])
|
| 75 |
+
|
| 76 |
+
rag_chain = qa_prompt | llm | StrOutputParser()
|
| 77 |
+
response = rag_chain.invoke({"context": sources_str, "question": question})
|
| 78 |
+
return {"messages": [AIMessage(content=response)], "user_input": question}
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def add_recommendations_pipeline_(
|
| 82 |
+
G: StateGraph,
|
| 83 |
+
reformulation_node_name: str = "reformulate",
|
| 84 |
+
search_node_name: str = "search_agent"
|
| 85 |
+
) -> None:
|
| 86 |
+
"""Adds execution sub-graph for recommendation engine flow. Graph changes are in-place.
|
| 87 |
+
|
| 88 |
+
Parameters
|
| 89 |
+
----------
|
| 90 |
+
G : StateGraph
|
| 91 |
+
Execution graph
|
| 92 |
+
reformulation_node_name : str, optional
|
| 93 |
+
Name of the node which reforumates input queries, by default "reformulate"
|
| 94 |
+
search_node_name : str, optional
|
| 95 |
+
Name of the node which executes document search + retrieval, by default "search_agent"
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
# Nodes for recommendation functionalities
|
| 99 |
+
G.add_node("detect_intent_with_llm", detect_intent_with_llm)
|
| 100 |
+
G.add_node("determine_context", determine_context)
|
| 101 |
+
G.add_node("make_recommendation", make_recommendation)
|
| 102 |
+
|
| 103 |
+
# Check for recommendation query first
|
| 104 |
+
# Execute until reaching END if user asks for recommendation
|
| 105 |
+
G.add_edge(reformulation_node_name, "detect_intent_with_llm")
|
| 106 |
+
G.add_conditional_edges(
|
| 107 |
+
source="detect_intent_with_llm",
|
| 108 |
+
path=lambda state: "determine_context" if state["intent"] in ["rfp", "funder"] else search_node_name,
|
| 109 |
+
path_map={
|
| 110 |
+
"determine_context": "determine_context",
|
| 111 |
+
search_node_name: search_node_name
|
| 112 |
+
},
|
| 113 |
+
)
|
| 114 |
+
G.add_edge("determine_context", "make_recommendation")
|
| 115 |
+
G.add_edge("make_recommendation", END)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def build_compute_graph(
|
| 119 |
+
llm: LLM,
|
| 120 |
+
indices: List[str],
|
| 121 |
+
enable_recommendations: bool = False
|
| 122 |
+
) -> StateGraph:
|
| 123 |
+
"""Execution graph builder, the output is the execution flow for an interaction with the assistant.
|
| 124 |
+
|
| 125 |
+
Parameters
|
| 126 |
+
----------
|
| 127 |
+
llm : LLM
|
| 128 |
+
indices : List[str]
|
| 129 |
+
Semantic index names to search over
|
| 130 |
+
enable_recommendations : bool, optional
|
| 131 |
+
Set to `True` to allow the flow to generate recommendations based on context, by default False
|
| 132 |
+
|
| 133 |
+
Returns
|
| 134 |
+
-------
|
| 135 |
+
StateGraph
|
| 136 |
+
Execution graph
|
| 137 |
+
"""
|
| 138 |
+
|
| 139 |
+
candid_retriever_tool = retriever_tool(indices=indices)
|
| 140 |
+
retrieve = ToolNode([candid_retriever_tool])
|
| 141 |
+
tools = [candid_retriever_tool]
|
| 142 |
+
|
| 143 |
+
G = StateGraph(AgentState)
|
| 144 |
+
|
| 145 |
+
G.add_node("reformulate", partial(reformulate_question_using_history, llm=llm))
|
| 146 |
+
G.add_node("search_agent", partial(search_agent, llm=llm, tools=tools))
|
| 147 |
+
G.add_node("retrieve", retrieve)
|
| 148 |
+
G.add_node("generate_with_context", partial(generate_with_context, llm=llm))
|
| 149 |
+
G.add_node("has_org_name", partial(has_org_name, llm=llm))
|
| 150 |
+
G.add_node("insert_org_link", insert_org_link)
|
| 151 |
+
|
| 152 |
+
if enable_recommendations:
|
| 153 |
+
add_recommendations_pipeline_(G, reformulation_node_name="reformulate", search_node_name="search_agent")
|
| 154 |
+
else:
|
| 155 |
+
G.add_edge("reformulate", "search_agent")
|
| 156 |
+
|
| 157 |
+
G.add_edge(START, "reformulate")
|
| 158 |
+
G.add_conditional_edges(
|
| 159 |
+
source="search_agent",
|
| 160 |
+
path=tools_condition,
|
| 161 |
+
path_map={
|
| 162 |
+
"tools": "retrieve",
|
| 163 |
+
END: "has_org_name",
|
| 164 |
+
},
|
| 165 |
+
)
|
| 166 |
+
G.add_edge("retrieve", "generate_with_context")
|
| 167 |
+
G.add_edge("generate_with_context", "has_org_name")
|
| 168 |
+
G.add_conditional_edges(
|
| 169 |
+
source="has_org_name",
|
| 170 |
+
path=lambda x: x["next"], # Now we're accessing the 'next' key from the dict
|
| 171 |
+
path_map={
|
| 172 |
+
"insert_org_link": "insert_org_link",
|
| 173 |
+
END: END
|
| 174 |
+
},
|
| 175 |
+
)
|
| 176 |
+
G.add_edge("insert_org_link", END)
|
| 177 |
+
return G
|
ask_candid/retrieval/elastic.py
CHANGED
|
@@ -1,14 +1,17 @@
|
|
| 1 |
-
from typing import List, Tuple, Dict, Iterable, Iterator, Optional, Any
|
| 2 |
from dataclasses import dataclass
|
| 3 |
from functools import partial
|
| 4 |
from itertools import groupby
|
| 5 |
|
|
|
|
|
|
|
| 6 |
from pydantic import BaseModel, Field
|
| 7 |
from langchain_core.documents import Document
|
| 8 |
from langchain_core.tools import Tool
|
| 9 |
|
| 10 |
from elasticsearch import Elasticsearch
|
| 11 |
|
|
|
|
| 12 |
from ask_candid.base.config.connections import SEMANTIC_ELASTIC_QA
|
| 13 |
from ask_candid.base.config.data import ElasticIndexMapping, ALL_INDICES
|
| 14 |
|
|
@@ -34,6 +37,21 @@ def build_text_expansion_query(
|
|
| 34 |
fields: Tuple[str],
|
| 35 |
model_id: str = ".elser_model_2_linux-x86_64"
|
| 36 |
) -> Dict[str, Any]:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
output = []
|
| 39 |
|
|
@@ -60,7 +78,21 @@ def build_text_expansion_query(
|
|
| 60 |
return {"query": {"bool": {"should": output}}}
|
| 61 |
|
| 62 |
|
| 63 |
-
def query_builder(query: str, indices: List[str]):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
queries = []
|
| 65 |
if indices is None:
|
| 66 |
indices = list(ALL_INDICES)
|
|
@@ -111,7 +143,19 @@ def query_builder(query: str, indices: List[str]):
|
|
| 111 |
return queries
|
| 112 |
|
| 113 |
|
| 114 |
-
def multi_search(queries: List[ElasticHitsResult]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 115 |
results = []
|
| 116 |
with Elasticsearch(
|
| 117 |
cloud_id=SEMANTIC_ELASTIC_QA.cloud_id,
|
|
@@ -132,13 +176,77 @@ def multi_search(queries: List[ElasticHitsResult]):
|
|
| 132 |
return results
|
| 133 |
|
| 134 |
|
| 135 |
-
def get_query_results(search_text: str, indices: Optional[List[str]] = None):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 136 |
queries = query_builder(query=search_text, indices=indices)
|
| 137 |
return multi_search(queries)
|
| 138 |
|
| 139 |
|
| 140 |
-
def
|
| 141 |
-
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
This will shuffle results
|
| 143 |
|
| 144 |
Parameters
|
|
@@ -151,6 +259,7 @@ def reranker(query_results: Iterable[ElasticHitsResult]) -> Iterator[ElasticHits
|
|
| 151 |
"""
|
| 152 |
|
| 153 |
results: List[ElasticHitsResult] = []
|
|
|
|
| 154 |
for _, data in groupby(query_results, key=lambda x: x.index):
|
| 155 |
data = list(data)
|
| 156 |
max_score = max(data, key=lambda x: x.score).score
|
|
@@ -160,19 +269,44 @@ def reranker(query_results: Iterable[ElasticHitsResult]) -> Iterator[ElasticHits
|
|
| 160 |
d.score = (d.score - min_score) / (max_score - min_score + 1e-9)
|
| 161 |
results.append(d)
|
| 162 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 163 |
yield from sorted(results, key=lambda x: x.score, reverse=True)
|
| 164 |
|
| 165 |
|
| 166 |
-
def get_results(user_input: str, indices: List[str]) -> List[
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 167 |
output = ["Search didn't return any Candid sources"]
|
| 168 |
-
page_content=[]
|
| 169 |
content = "Search didn't return any Candid sources"
|
| 170 |
results = get_query_results(search_text=user_input, indices=indices)
|
| 171 |
if results:
|
| 172 |
-
output = get_reranked_results(results)
|
| 173 |
for doc in output:
|
| 174 |
page_content.append(doc.page_content)
|
| 175 |
-
content = "
|
|
|
|
| 176 |
# for the tool we need to return a tuple for content_and_artifact type
|
| 177 |
return content, output
|
| 178 |
|
|
@@ -197,27 +331,38 @@ def get_context(field_name: str, hit: ElasticHitsResult, context_length: int = 1
|
|
| 197 |
chunks_with_context = []
|
| 198 |
long_text = hit.source.get(f"{field_name}", "")
|
| 199 |
inner_hits_field = f"embeddings.{field_name}.chunks"
|
| 200 |
-
|
| 201 |
-
found_chunks = inner_hits.get(inner_hits_field, {})
|
| 202 |
if found_chunks:
|
| 203 |
hits = found_chunks.get("hits", {}).get("hits", [])
|
| 204 |
for h in hits:
|
| 205 |
chunk = h.get("fields", {})[inner_hits_field][0]["chunk"][0]
|
| 206 |
-
|
|
|
|
|
|
|
|
|
|
| 207 |
# Find the start and end indices of the chunk in the large text
|
| 208 |
start_index = long_text.find(chunk)
|
| 209 |
if start_index != -1: # Chunk is found
|
| 210 |
end_index = start_index + len(chunk)
|
| 211 |
pre_start_index = max(0, start_index - context_length)
|
| 212 |
post_end_index = min(len(long_text), end_index + context_length)
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
|
| 217 |
-
return chunks_with_context_txt
|
| 218 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 219 |
|
| 220 |
-
def process_hit(hit: ElasticHitsResult) -> Document | None:
|
| 221 |
if "issuelab-elser" in hit.index:
|
| 222 |
combined_item_description = hit.source.get("combined_item_description", "") # title inside
|
| 223 |
description = hit.source.get("description", "")
|
|
@@ -300,17 +445,43 @@ def process_hit(hit: ElasticHitsResult) -> Document | None:
|
|
| 300 |
return doc
|
| 301 |
|
| 302 |
|
| 303 |
-
def get_reranked_results(results: List[ElasticHitsResult]) -> List[Document]:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 304 |
output = []
|
| 305 |
-
for r in reranker(results):
|
| 306 |
hit = process_hit(r)
|
| 307 |
-
|
|
|
|
| 308 |
return output
|
| 309 |
|
| 310 |
|
| 311 |
def retriever_tool(indices: List[str]) -> Tool:
|
| 312 |
-
|
| 313 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 314 |
return Tool(
|
| 315 |
name="retrieve_social_sector_information",
|
| 316 |
func=partial(get_results, indices=indices),
|
|
|
|
| 1 |
+
from typing import List, Tuple, Dict, Iterable, Iterator, Optional, Union, Any
|
| 2 |
from dataclasses import dataclass
|
| 3 |
from functools import partial
|
| 4 |
from itertools import groupby
|
| 5 |
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
from pydantic import BaseModel, Field
|
| 9 |
from langchain_core.documents import Document
|
| 10 |
from langchain_core.tools import Tool
|
| 11 |
|
| 12 |
from elasticsearch import Elasticsearch
|
| 13 |
|
| 14 |
+
from ask_candid.services.small_lm import CandidSLM
|
| 15 |
from ask_candid.base.config.connections import SEMANTIC_ELASTIC_QA
|
| 16 |
from ask_candid.base.config.data import ElasticIndexMapping, ALL_INDICES
|
| 17 |
|
|
|
|
| 37 |
fields: Tuple[str],
|
| 38 |
model_id: str = ".elser_model_2_linux-x86_64"
|
| 39 |
) -> Dict[str, Any]:
|
| 40 |
+
"""Builds a valid Elasticsearch text expansion query payload
|
| 41 |
+
|
| 42 |
+
Parameters
|
| 43 |
+
----------
|
| 44 |
+
query : str
|
| 45 |
+
Search context string
|
| 46 |
+
fields : Tuple[str]
|
| 47 |
+
Semantic text field names
|
| 48 |
+
model_id : str, optional
|
| 49 |
+
ID of model deployed in Elasticsearch, by default ".elser_model_2_linux-x86_64"
|
| 50 |
+
|
| 51 |
+
Returns
|
| 52 |
+
-------
|
| 53 |
+
Dict[str, Any]
|
| 54 |
+
"""
|
| 55 |
|
| 56 |
output = []
|
| 57 |
|
|
|
|
| 78 |
return {"query": {"bool": {"should": output}}}
|
| 79 |
|
| 80 |
|
| 81 |
+
def query_builder(query: str, indices: List[str]) -> List[Dict[str, Any]]:
|
| 82 |
+
"""Builds Elasticsearch multi-search query payload
|
| 83 |
+
|
| 84 |
+
Parameters
|
| 85 |
+
----------
|
| 86 |
+
query : str
|
| 87 |
+
Search context string
|
| 88 |
+
indices : List[str]
|
| 89 |
+
Semantic index names to search over
|
| 90 |
+
|
| 91 |
+
Returns
|
| 92 |
+
-------
|
| 93 |
+
List[Dict[str, Any]]
|
| 94 |
+
"""
|
| 95 |
+
|
| 96 |
queries = []
|
| 97 |
if indices is None:
|
| 98 |
indices = list(ALL_INDICES)
|
|
|
|
| 143 |
return queries
|
| 144 |
|
| 145 |
|
| 146 |
+
def multi_search(queries: List[Dict[str, Any]]) -> List[ElasticHitsResult]:
|
| 147 |
+
"""Runs multi-search query
|
| 148 |
+
|
| 149 |
+
Parameters
|
| 150 |
+
----------
|
| 151 |
+
queries : List[Dict[str, Any]]
|
| 152 |
+
Pre-built multi-search query payload
|
| 153 |
+
|
| 154 |
+
Returns
|
| 155 |
+
-------
|
| 156 |
+
List[ElasticHitsResult]
|
| 157 |
+
"""
|
| 158 |
+
|
| 159 |
results = []
|
| 160 |
with Elasticsearch(
|
| 161 |
cloud_id=SEMANTIC_ELASTIC_QA.cloud_id,
|
|
|
|
| 176 |
return results
|
| 177 |
|
| 178 |
|
| 179 |
+
def get_query_results(search_text: str, indices: Optional[List[str]] = None) -> List[ElasticHitsResult]:
|
| 180 |
+
"""Builds and executes Elasticsearch data queries from a search string.
|
| 181 |
+
|
| 182 |
+
Parameters
|
| 183 |
+
----------
|
| 184 |
+
search_text : str
|
| 185 |
+
Search context string
|
| 186 |
+
indices : Optional[List[str]], optional
|
| 187 |
+
Semantic index names to search over, by default None
|
| 188 |
+
|
| 189 |
+
Returns
|
| 190 |
+
-------
|
| 191 |
+
List[ElasticHitsResult]
|
| 192 |
+
"""
|
| 193 |
+
|
| 194 |
queries = query_builder(query=search_text, indices=indices)
|
| 195 |
return multi_search(queries)
|
| 196 |
|
| 197 |
|
| 198 |
+
def retrieved_text(hits: Dict[str, Any]) -> str:
|
| 199 |
+
"""Extracts retrieved sub-texts from documents which are strong hits from semantic queries for the purpose of
|
| 200 |
+
re-scoring by a secondary language model.
|
| 201 |
+
|
| 202 |
+
Parameters
|
| 203 |
+
----------
|
| 204 |
+
hits : Dict[str, Any]
|
| 205 |
+
|
| 206 |
+
Returns
|
| 207 |
+
-------
|
| 208 |
+
str
|
| 209 |
+
"""
|
| 210 |
+
|
| 211 |
+
text = []
|
| 212 |
+
for _, v in hits.items():
|
| 213 |
+
for h in (v.get("hits", {}).get("hits") or []):
|
| 214 |
+
for _, field in h.get("fields", {}).items():
|
| 215 |
+
for chunk in field:
|
| 216 |
+
if chunk.get("chunk"):
|
| 217 |
+
text.extend(chunk["chunk"])
|
| 218 |
+
return '\n'.join(text)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def cosine_rescore(query: str, contexts: List[str]) -> List[float]:
|
| 222 |
+
"""Computes cosine scores between retrieved contexts and the original query to re-score results based on overall
|
| 223 |
+
relevance to the original query.
|
| 224 |
+
|
| 225 |
+
Parameters
|
| 226 |
+
----------
|
| 227 |
+
query : str
|
| 228 |
+
Search context string
|
| 229 |
+
contexts : List[str]
|
| 230 |
+
Semantic field sub-texts, order is by document retrieved from the original multi-search query.
|
| 231 |
+
|
| 232 |
+
Returns
|
| 233 |
+
-------
|
| 234 |
+
List[float]
|
| 235 |
+
Scores in the same order as the input document contexts
|
| 236 |
+
"""
|
| 237 |
+
|
| 238 |
+
nlp = CandidSLM()
|
| 239 |
+
X = nlp.encode([query, *contexts]).vectors
|
| 240 |
+
X = F.normalize(X, dim=-1, p=2.)
|
| 241 |
+
cosine = X[1:] @ X[:1].T
|
| 242 |
+
return cosine.flatten().cpu().numpy().tolist()
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
def reranker(
|
| 246 |
+
query_results: Iterable[ElasticHitsResult],
|
| 247 |
+
search_text: Optional[str] = None
|
| 248 |
+
) -> Iterator[ElasticHitsResult]:
|
| 249 |
+
"""Reranks Elasticsearch hits coming from multiple indices/queries which may have scores on different scales.
|
| 250 |
This will shuffle results
|
| 251 |
|
| 252 |
Parameters
|
|
|
|
| 259 |
"""
|
| 260 |
|
| 261 |
results: List[ElasticHitsResult] = []
|
| 262 |
+
texts: List[str] = []
|
| 263 |
for _, data in groupby(query_results, key=lambda x: x.index):
|
| 264 |
data = list(data)
|
| 265 |
max_score = max(data, key=lambda x: x.score).score
|
|
|
|
| 269 |
d.score = (d.score - min_score) / (max_score - min_score + 1e-9)
|
| 270 |
results.append(d)
|
| 271 |
|
| 272 |
+
if search_text:
|
| 273 |
+
text = retrieved_text(d.inner_hits)
|
| 274 |
+
texts.append(text)
|
| 275 |
+
|
| 276 |
+
# if search_text and len(texts) == len(results):
|
| 277 |
+
# scores = cosine_rescore(search_text, texts)
|
| 278 |
+
# for r, s in zip(results, scores):
|
| 279 |
+
# r.score = s
|
| 280 |
+
|
| 281 |
yield from sorted(results, key=lambda x: x.score, reverse=True)
|
| 282 |
|
| 283 |
|
| 284 |
+
def get_results(user_input: str, indices: List[str]) -> Tuple[str, List[Document]]:
|
| 285 |
+
"""End-to-end search and re-rank function.
|
| 286 |
+
|
| 287 |
+
Parameters
|
| 288 |
+
----------
|
| 289 |
+
user_input : str
|
| 290 |
+
Search context string
|
| 291 |
+
indices : List[str]
|
| 292 |
+
Semantic index names to search over
|
| 293 |
+
|
| 294 |
+
Returns
|
| 295 |
+
-------
|
| 296 |
+
Tuple[str, List[Document]]
|
| 297 |
+
(concatenated text from search results, documents list)
|
| 298 |
+
"""
|
| 299 |
+
|
| 300 |
output = ["Search didn't return any Candid sources"]
|
| 301 |
+
page_content = []
|
| 302 |
content = "Search didn't return any Candid sources"
|
| 303 |
results = get_query_results(search_text=user_input, indices=indices)
|
| 304 |
if results:
|
| 305 |
+
output = get_reranked_results(results, search_text=user_input)
|
| 306 |
for doc in output:
|
| 307 |
page_content.append(doc.page_content)
|
| 308 |
+
content = "\n\n".join(page_content)
|
| 309 |
+
|
| 310 |
# for the tool we need to return a tuple for content_and_artifact type
|
| 311 |
return content, output
|
| 312 |
|
|
|
|
| 331 |
chunks_with_context = []
|
| 332 |
long_text = hit.source.get(f"{field_name}", "")
|
| 333 |
inner_hits_field = f"embeddings.{field_name}.chunks"
|
| 334 |
+
found_chunks = hit.inner_hits.get(inner_hits_field, {})
|
|
|
|
| 335 |
if found_chunks:
|
| 336 |
hits = found_chunks.get("hits", {}).get("hits", [])
|
| 337 |
for h in hits:
|
| 338 |
chunk = h.get("fields", {})[inner_hits_field][0]["chunk"][0]
|
| 339 |
+
|
| 340 |
+
# cutting the middle because we may have tokenizing artifacts there
|
| 341 |
+
chunk = chunk[3: -3]
|
| 342 |
+
|
| 343 |
# Find the start and end indices of the chunk in the large text
|
| 344 |
start_index = long_text.find(chunk)
|
| 345 |
if start_index != -1: # Chunk is found
|
| 346 |
end_index = start_index + len(chunk)
|
| 347 |
pre_start_index = max(0, start_index - context_length)
|
| 348 |
post_end_index = min(len(long_text), end_index + context_length)
|
| 349 |
+
chunks_with_context.append(long_text[pre_start_index:post_end_index])
|
| 350 |
+
|
| 351 |
+
return '\n\n'.join(chunks_with_context)
|
| 352 |
|
|
|
|
| 353 |
|
| 354 |
+
def process_hit(hit: ElasticHitsResult) -> Union[Document, None]:
|
| 355 |
+
"""Parse Elasticsearch hit results into data structures handled by the RAG pipeline.
|
| 356 |
+
|
| 357 |
+
Parameters
|
| 358 |
+
----------
|
| 359 |
+
hit : ElasticHitsResult
|
| 360 |
+
|
| 361 |
+
Returns
|
| 362 |
+
-------
|
| 363 |
+
Union[Document, None]
|
| 364 |
+
"""
|
| 365 |
|
|
|
|
| 366 |
if "issuelab-elser" in hit.index:
|
| 367 |
combined_item_description = hit.source.get("combined_item_description", "") # title inside
|
| 368 |
description = hit.source.get("description", "")
|
|
|
|
| 445 |
return doc
|
| 446 |
|
| 447 |
|
| 448 |
+
def get_reranked_results(results: List[ElasticHitsResult], search_text: Optional[str] = None) -> List[Document]:
|
| 449 |
+
"""Run data re-ranking and document building for tool usage.
|
| 450 |
+
|
| 451 |
+
Parameters
|
| 452 |
+
----------
|
| 453 |
+
results : List[ElasticHitsResult]
|
| 454 |
+
search_text : Optional[str], optional
|
| 455 |
+
Search context string, by default None
|
| 456 |
+
|
| 457 |
+
Returns
|
| 458 |
+
-------
|
| 459 |
+
List[Document]
|
| 460 |
+
"""
|
| 461 |
+
|
| 462 |
output = []
|
| 463 |
+
for r in reranker(results, search_text=search_text):
|
| 464 |
hit = process_hit(r)
|
| 465 |
+
if hit is not None:
|
| 466 |
+
output.append(hit)
|
| 467 |
return output
|
| 468 |
|
| 469 |
|
| 470 |
def retriever_tool(indices: List[str]) -> Tool:
|
| 471 |
+
"""Tool component for use in conditional edge building for RAG execution graph.
|
| 472 |
+
Cannot use `create_retriever_tool` because it only provides content losing all metadata on the way
|
| 473 |
+
https://python.langchain.com/docs/how_to/custom_tools/#returning-artifacts-of-tool-execution
|
| 474 |
+
|
| 475 |
+
Parameters
|
| 476 |
+
----------
|
| 477 |
+
indices : List[str]
|
| 478 |
+
Semantic index names to search over
|
| 479 |
+
|
| 480 |
+
Returns
|
| 481 |
+
-------
|
| 482 |
+
Tool
|
| 483 |
+
"""
|
| 484 |
+
|
| 485 |
return Tool(
|
| 486 |
name="retrieve_social_sector_information",
|
| 487 |
func=partial(get_results, indices=indices),
|
ask_candid/services/small_lm.py
CHANGED
|
@@ -15,6 +15,7 @@ class Encoding:
|
|
| 15 |
|
| 16 |
class CandidSLM(LambdaInvokeBase):
|
| 17 |
"""Wrapper around Candid's custom small language model.
|
|
|
|
| 18 |
This services includes:
|
| 19 |
* text encoding
|
| 20 |
* document summarization
|
|
@@ -43,7 +44,7 @@ class CandidSLM(LambdaInvokeBase):
|
|
| 43 |
)
|
| 44 |
|
| 45 |
def encode(self, text: List[str]) -> Encoding:
|
| 46 |
-
response = self._submit_request({"text": text})
|
| 47 |
|
| 48 |
output = Encoding(
|
| 49 |
inputs=(response.get("inputs") or []),
|
|
|
|
| 15 |
|
| 16 |
class CandidSLM(LambdaInvokeBase):
|
| 17 |
"""Wrapper around Candid's custom small language model.
|
| 18 |
+
For more details see https://dev.azure.com/guidestar/DataScience/_git/graph-ai?path=/releases/language.
|
| 19 |
This services includes:
|
| 20 |
* text encoding
|
| 21 |
* document summarization
|
|
|
|
| 44 |
)
|
| 45 |
|
| 46 |
def encode(self, text: List[str]) -> Encoding:
|
| 47 |
+
response = self._submit_request({"text": text, "path": self.Tasks.ENCODE.value})
|
| 48 |
|
| 49 |
output = Encoding(
|
| 50 |
inputs=(response.get("inputs") or []),
|
ask_candid/tools/org_seach.py
CHANGED
|
@@ -1,18 +1,26 @@
|
|
| 1 |
from typing import List
|
|
|
|
| 2 |
import re
|
| 3 |
|
| 4 |
from fuzzywuzzy import fuzz
|
| 5 |
|
| 6 |
from langchain.output_parsers.openai_tools import JsonOutputToolsParser
|
| 7 |
-
from langchain_openai.chat_models import ChatOpenAI
|
| 8 |
from langchain_core.runnables import RunnableSequence
|
| 9 |
from langchain_core.prompts import ChatPromptTemplate
|
|
|
|
|
|
|
|
|
|
| 10 |
from pydantic import BaseModel, Field
|
| 11 |
|
|
|
|
| 12 |
from ask_candid.services.org_search import OrgSearch
|
| 13 |
-
from ask_candid.base.config.rest import OPENAI
|
| 14 |
|
| 15 |
search = OrgSearch()
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
|
| 18 |
class OrganizationNames(BaseModel):
|
|
@@ -20,7 +28,7 @@ class OrganizationNames(BaseModel):
|
|
| 20 |
orgnames: List[str] = Field(description="List of organization names")
|
| 21 |
|
| 22 |
|
| 23 |
-
def extract_org_links_from_chatbot(chatbot_output: str):
|
| 24 |
"""
|
| 25 |
Extracts a list of organization names from the provided text.
|
| 26 |
|
|
@@ -51,9 +59,10 @@ def extract_org_links_from_chatbot(chatbot_output: str):
|
|
| 51 |
|
| 52 |
try:
|
| 53 |
parser = JsonOutputToolsParser()
|
| 54 |
-
llm = ChatOpenAI(model="gpt-4o", api_key=OPENAI["key"]).bind_tools([OrganizationNames])
|
|
|
|
| 55 |
prompt = ChatPromptTemplate.from_template(prompt)
|
| 56 |
-
chain = RunnableSequence(prompt,
|
| 57 |
|
| 58 |
# Run the chain with the input data
|
| 59 |
result = chain.invoke({"chatbot_output": chatbot_output})
|
|
@@ -192,3 +201,44 @@ def embed_org_links_in_text(input_text: str, org_link_dict: dict):
|
|
| 192 |
return input_text
|
| 193 |
|
| 194 |
return input_text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
from typing import List
|
| 2 |
+
import logging
|
| 3 |
import re
|
| 4 |
|
| 5 |
from fuzzywuzzy import fuzz
|
| 6 |
|
| 7 |
from langchain.output_parsers.openai_tools import JsonOutputToolsParser
|
| 8 |
+
# from langchain_openai.chat_models import ChatOpenAI
|
| 9 |
from langchain_core.runnables import RunnableSequence
|
| 10 |
from langchain_core.prompts import ChatPromptTemplate
|
| 11 |
+
from langchain_core.language_models.llms import LLM
|
| 12 |
+
from langchain_core.messages import AIMessage
|
| 13 |
+
from langgraph.constants import END
|
| 14 |
from pydantic import BaseModel, Field
|
| 15 |
|
| 16 |
+
from ask_candid.agents.schema import AgentState
|
| 17 |
from ask_candid.services.org_search import OrgSearch
|
| 18 |
+
# from ask_candid.base.config.rest import OPENAI
|
| 19 |
|
| 20 |
search = OrgSearch()
|
| 21 |
+
logging.basicConfig(format="[%(levelname)s] (%(asctime)s) :: %(message)s")
|
| 22 |
+
logger = logging.getLogger(__name__)
|
| 23 |
+
logger.setLevel(logging.INFO)
|
| 24 |
|
| 25 |
|
| 26 |
class OrganizationNames(BaseModel):
|
|
|
|
| 28 |
orgnames: List[str] = Field(description="List of organization names")
|
| 29 |
|
| 30 |
|
| 31 |
+
def extract_org_links_from_chatbot(chatbot_output: str, llm: LLM):
|
| 32 |
"""
|
| 33 |
Extracts a list of organization names from the provided text.
|
| 34 |
|
|
|
|
| 59 |
|
| 60 |
try:
|
| 61 |
parser = JsonOutputToolsParser()
|
| 62 |
+
# llm = ChatOpenAI(model="gpt-4o", api_key=OPENAI["key"]).bind_tools([OrganizationNames])
|
| 63 |
+
model = llm.bind_tools([OrganizationNames])
|
| 64 |
prompt = ChatPromptTemplate.from_template(prompt)
|
| 65 |
+
chain = RunnableSequence(prompt, model, parser)
|
| 66 |
|
| 67 |
# Run the chain with the input data
|
| 68 |
result = chain.invoke({"chatbot_output": chatbot_output})
|
|
|
|
| 201 |
return input_text
|
| 202 |
|
| 203 |
return input_text
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def has_org_name(state: AgentState, llm: LLM) -> AgentState:
|
| 207 |
+
"""
|
| 208 |
+
Processes the latest message to extract organization links and determine the next step.
|
| 209 |
+
|
| 210 |
+
Args:
|
| 211 |
+
state (AgentState): The current state of the agent, including a list of messages.
|
| 212 |
+
|
| 213 |
+
Returns:
|
| 214 |
+
dict: A dictionary with the next agent action and, if available, a dictionary of organization links.
|
| 215 |
+
"""
|
| 216 |
+
logger.info("---HAS ORG NAMES?---")
|
| 217 |
+
messages = state["messages"]
|
| 218 |
+
last_message = messages[-1].content
|
| 219 |
+
output_list = extract_org_links_from_chatbot(last_message, llm=llm)
|
| 220 |
+
link_dict = generate_org_link_dict(output_list) if output_list else {}
|
| 221 |
+
if link_dict:
|
| 222 |
+
logger.info("---FOUND ORG NAMES---")
|
| 223 |
+
return {"next": "insert_org_link", "org_dict": link_dict}
|
| 224 |
+
logger.info("---NO ORG NAMES FOUND---")
|
| 225 |
+
return {"next": END, "messages": messages}
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def insert_org_link(state: AgentState) -> AgentState:
|
| 229 |
+
"""
|
| 230 |
+
Embeds organization links in the latest message content and returns it as an AI message.
|
| 231 |
+
|
| 232 |
+
Args:
|
| 233 |
+
state (dict): The current state, including the organization links and latest message.
|
| 234 |
+
|
| 235 |
+
Returns:
|
| 236 |
+
dict: A dictionary with the updated message content as an AIMessage.
|
| 237 |
+
"""
|
| 238 |
+
logger.info("---INSERT ORG LINKS---")
|
| 239 |
+
messages = state["messages"]
|
| 240 |
+
last_message = messages[-1].content
|
| 241 |
+
messages.pop(-1) # Deleting the original message because we will append the same one but with links
|
| 242 |
+
link_dict = state["org_dict"]
|
| 243 |
+
last_message = embed_org_links_in_text(last_message, link_dict)
|
| 244 |
+
return {"messages": [AIMessage(content=last_message)]}
|
ask_candid/tools/recommendation.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
from openai import OpenAI
|
| 5 |
+
import requests
|
| 6 |
+
|
| 7 |
+
from ask_candid.agents.schema import AgentState, Context
|
| 8 |
+
from ask_candid.base.config.rest import OPENAI
|
| 9 |
+
|
| 10 |
+
logging.basicConfig(format="[%(levelname)s] (%(asctime)s) :: %(message)s")
|
| 11 |
+
logger = logging.getLogger(__name__)
|
| 12 |
+
logger.setLevel(logging.INFO)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def detect_intent_with_llm(state: AgentState) -> AgentState:
|
| 16 |
+
"""Detect query intent (which type of recommendation) and update the state."""
|
| 17 |
+
logger.info("---DETECT INTENT---")
|
| 18 |
+
client = OpenAI(api_key=OPENAI['key'])
|
| 19 |
+
# query = state["messages"][-1]["content"]
|
| 20 |
+
query = state["messages"][-1].content
|
| 21 |
+
prompt = f"""Classify the following query as one of the following categories:
|
| 22 |
+
- 'none': The query is not asking for funding recommendations.
|
| 23 |
+
- 'funder': The query is asking for recommendations about funders, such as foundations or donors, who might provide longer-term or general funding.
|
| 24 |
+
- 'rfp': The query is asking for recommendations about specific, active Requests for Proposals (RFPs) that typically focus on short-term, recent opportunities with a deadline.
|
| 25 |
+
|
| 26 |
+
Your classification should consider:
|
| 27 |
+
1. RFPs often focus on active and time-bound opportunities for specific projects or programs.
|
| 28 |
+
2. Funders refer to broader, long-term funding sources like organizations or individuals who offer grants.
|
| 29 |
+
|
| 30 |
+
Query: "{query}"
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
response = client.chat.completions.create(
|
| 34 |
+
# model="gpt-4-turbo",
|
| 35 |
+
model="gpt-4o",
|
| 36 |
+
messages=[{"role": "system", "content": prompt}],
|
| 37 |
+
max_tokens=10,
|
| 38 |
+
stop=["\n"]
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
intent = response.choices[0].message.content.strip().lower()
|
| 42 |
+
state["intent"] = intent.strip("'").strip('"') # Remove extra quotes
|
| 43 |
+
return state
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def determine_context(state: AgentState) -> AgentState:
|
| 47 |
+
"""Extract subject/geography/population codes and update the state."""
|
| 48 |
+
logger.info("---GETTING RECOMMENDATION CONTEXT---")
|
| 49 |
+
query = state["messages"][-1].content
|
| 50 |
+
|
| 51 |
+
subject_codes, population_codes, geo_ids = [], [], []
|
| 52 |
+
|
| 53 |
+
# subject and population
|
| 54 |
+
autocoding_headers = {
|
| 55 |
+
'x-api-key': os.getenv("AUTOCODING_API_KEY"),
|
| 56 |
+
'Content-Type': 'application/json'
|
| 57 |
+
}
|
| 58 |
+
autocoding_params = {
|
| 59 |
+
'text': query,
|
| 60 |
+
'taxonomy': 'pcs-v3'
|
| 61 |
+
}
|
| 62 |
+
autocoding_response = requests.get(
|
| 63 |
+
os.getenv("AUTOCODING_API_URL"),
|
| 64 |
+
headers=autocoding_headers,
|
| 65 |
+
params=autocoding_params,
|
| 66 |
+
timeout=30
|
| 67 |
+
)
|
| 68 |
+
if autocoding_response.status_code == 200:
|
| 69 |
+
returned_pcs = autocoding_response.json()["data"]
|
| 70 |
+
population_codes = [item['full_code'] for item in returned_pcs.get("population", [])]
|
| 71 |
+
subject_codes = [item['full_code'] for item in returned_pcs.get("subject", [])]
|
| 72 |
+
|
| 73 |
+
# geography
|
| 74 |
+
geo_headers = {
|
| 75 |
+
'x-api-key': os.getenv("GEO_API_KEY"),
|
| 76 |
+
'Content-Type': 'application/json'
|
| 77 |
+
}
|
| 78 |
+
geo_data = {
|
| 79 |
+
'text': query
|
| 80 |
+
}
|
| 81 |
+
geo_response = requests.post(os.getenv("GEO_API_URL"), headers=geo_headers, json=geo_data, timeout=30)
|
| 82 |
+
if geo_response.status_code == 200:
|
| 83 |
+
entities = geo_response.json()['data']['entities']
|
| 84 |
+
geo_ids = [entity['geo']['id'] for entity in entities if 'id' in entity['geo']]
|
| 85 |
+
|
| 86 |
+
state["context"] = Context(
|
| 87 |
+
subject=subject_codes,
|
| 88 |
+
population=population_codes,
|
| 89 |
+
geography=geo_ids
|
| 90 |
+
)
|
| 91 |
+
return state
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def make_recommendation(state: AgentState) -> AgentState:
|
| 95 |
+
"""Make an API call based on the extracted context and update the state."""
|
| 96 |
+
# query = state["messages"][-1]["content"]
|
| 97 |
+
logger.info("---RECOMMENDING---")
|
| 98 |
+
org_id = "6908122"
|
| 99 |
+
funder_or_rfp = state["intent"]
|
| 100 |
+
|
| 101 |
+
# Extract context
|
| 102 |
+
contexts = state["context"]
|
| 103 |
+
subject_codes = contexts.get("subject", [])
|
| 104 |
+
population_codes = contexts.get("population", [])
|
| 105 |
+
geo_ids = contexts.get("geography", [])
|
| 106 |
+
|
| 107 |
+
# Prepare parameters
|
| 108 |
+
params = {
|
| 109 |
+
"subjects": ",".join(subject_codes),
|
| 110 |
+
"geos": ",".join([str(geo) for geo in geo_ids]),
|
| 111 |
+
"populations": ",".join(population_codes)
|
| 112 |
+
}
|
| 113 |
+
headers = {"x-api-key": os.getenv("FUNDER_REC_API_KEY")}
|
| 114 |
+
base_url = os.getenv("FUNDER_REC_API_URL")
|
| 115 |
+
|
| 116 |
+
# Initialize response
|
| 117 |
+
response = None
|
| 118 |
+
|
| 119 |
+
recommendation_display_text = ""
|
| 120 |
+
|
| 121 |
+
try:
|
| 122 |
+
# Make the API call based on intent
|
| 123 |
+
if funder_or_rfp == "funder":
|
| 124 |
+
response = requests.get(base_url, headers=headers, params=params, timeout=30)
|
| 125 |
+
elif funder_or_rfp == "rfp":
|
| 126 |
+
params["candid_entity_id"] = org_id #placeholder
|
| 127 |
+
response = requests.get(f"{base_url}/rfp", headers=headers, params=params, timeout=30)
|
| 128 |
+
else:
|
| 129 |
+
# Handle unknown intent
|
| 130 |
+
state["recommendation"] = "Unknown intent. Intent 'funder' or 'rfp' expected."
|
| 131 |
+
return state
|
| 132 |
+
|
| 133 |
+
# Validate response
|
| 134 |
+
if response and response.status_code == 200:
|
| 135 |
+
recommendations = response.json().get("recommendations", [])
|
| 136 |
+
if recommendations:
|
| 137 |
+
if funder_or_rfp == "funder":
|
| 138 |
+
# Format recommendations
|
| 139 |
+
recommendation_display_text = "Here are the top 10 recommendations. Click their profiles to learn more:\n" + "\n".join([
|
| 140 |
+
f"{recommendation['funder_data']['main_sort_name']} - Profile: https://app.candid.org/profile/{recommendation['funder_id']}"
|
| 141 |
+
for recommendation in recommendations
|
| 142 |
+
])
|
| 143 |
+
elif funder_or_rfp == "rfp":
|
| 144 |
+
recommendation_display_text = "Here are the top recommendations:\n" + "\n".join([
|
| 145 |
+
f"Title: {rec['title']}\n"
|
| 146 |
+
f"Funder: {rec['funder_name']}\n"
|
| 147 |
+
f"Amount: {rec.get('amount', 'Not specified')}\n"
|
| 148 |
+
f"Description: {rec.get('description', 'No description available')}\n"
|
| 149 |
+
f"Deadline: {rec.get('deadline', 'No deadline provided')}\n"
|
| 150 |
+
f"Application URL: {rec.get('application_url', 'No URL available')}\n"
|
| 151 |
+
for rec in recommendations
|
| 152 |
+
])
|
| 153 |
+
else:
|
| 154 |
+
# No recommendations found
|
| 155 |
+
recommendation_display_text = "No recommendations were found for your query. Please try refining your search criteria."
|
| 156 |
+
elif response and response.status_code == 400:
|
| 157 |
+
# Handle bad request
|
| 158 |
+
error_details = response.json()
|
| 159 |
+
recommendation_display_text = (
|
| 160 |
+
"An error occurred while processing your request. "
|
| 161 |
+
f"Details: {error_details.get('message', 'Unknown error.')}"
|
| 162 |
+
)
|
| 163 |
+
elif response:
|
| 164 |
+
# Handle other unexpected status codes
|
| 165 |
+
recommendation_display_text = (
|
| 166 |
+
f"An unexpected error occurred (Status Code: {response.status_code}). "
|
| 167 |
+
"Please try again later or contact support if the problem persists."
|
| 168 |
+
)
|
| 169 |
+
else:
|
| 170 |
+
# Handle case where response is None
|
| 171 |
+
recommendation_display_text = "No response from the server. Please check your connection or try again later."
|
| 172 |
+
|
| 173 |
+
except requests.exceptions.RequestException as e:
|
| 174 |
+
# Handle network-related errors
|
| 175 |
+
recommendation_display_text = (
|
| 176 |
+
"A network error occurred while trying to connect to the recommendation service. "
|
| 177 |
+
f"Details: {str(e)}"
|
| 178 |
+
)
|
| 179 |
+
except Exception as e:
|
| 180 |
+
# Handle other unexpected errors
|
| 181 |
+
print(params)
|
| 182 |
+
recommendation_display_text = (
|
| 183 |
+
"An unexpected error occurred while processing your request. "
|
| 184 |
+
f"Details: {str(e)}"
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# Update state with recommendations or error messages
|
| 188 |
+
state["recommendation"] = recommendation_display_text
|
| 189 |
+
return state
|
ask_candid/tools/search.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
from langchain_core.language_models.llms import LLM
|
| 5 |
+
from langchain_core.tools import Tool
|
| 6 |
+
|
| 7 |
+
from ask_candid.agents.schema import AgentState
|
| 8 |
+
|
| 9 |
+
logging.basicConfig(format="[%(levelname)s] (%(asctime)s) :: %(message)s")
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
logger.setLevel(logging.INFO)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def search_agent(state, llm: LLM, tools: List[Tool]) -> AgentState:
|
| 15 |
+
"""Invokes the agent model to generate a response based on the current state. Given
|
| 16 |
+
the question, it will decide to retrieve using the retriever tool, or simply end.
|
| 17 |
+
|
| 18 |
+
Parameters
|
| 19 |
+
----------
|
| 20 |
+
state : _type_
|
| 21 |
+
The current state
|
| 22 |
+
llm : LLM
|
| 23 |
+
tools : List[Tool]
|
| 24 |
+
|
| 25 |
+
Returns
|
| 26 |
+
-------
|
| 27 |
+
AgentState
|
| 28 |
+
The updated state with the agent response appended to messages
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
logger.info("---SEARCH AGENT---")
|
| 32 |
+
messages = state["messages"]
|
| 33 |
+
question = messages[-1].content
|
| 34 |
+
|
| 35 |
+
model = llm.bind_tools(tools)
|
| 36 |
+
response = model.invoke(messages)
|
| 37 |
+
# return a list, because this will get added to the existing list
|
| 38 |
+
return {"messages": [response], "user_input": question}
|
static/chatStyle.css
CHANGED
|
@@ -18,21 +18,22 @@
|
|
| 18 |
}
|
| 19 |
|
| 20 |
.source-item {
|
| 21 |
-
display: block;
|
| 22 |
min-width: 100px;
|
| 23 |
-
max-width:
|
|
|
|
| 24 |
height: fit-content;
|
| 25 |
background-color: #febe10;
|
| 26 |
color: black;
|
| 27 |
padding: 5px;
|
| 28 |
text-align: center;
|
| 29 |
border-radius: 5px;
|
| 30 |
-
box-shadow: 0 2px 5px 0 rgba(0, 0, 0,0.2);
|
| 31 |
font-size: medium;
|
| 32 |
}
|
| 33 |
|
| 34 |
.ssearch-source {
|
| 35 |
-
text-decoration: none;
|
| 36 |
box-sizing: border-box;
|
| 37 |
}
|
| 38 |
|
|
@@ -42,7 +43,7 @@ button.upload-button.svelte-1d7elt4 {
|
|
| 42 |
|
| 43 |
.candid-org-link {
|
| 44 |
font-weight: bold;
|
| 45 |
-
text-decoration: none;
|
| 46 |
}
|
| 47 |
|
| 48 |
.candid-app-link {
|
|
|
|
| 18 |
}
|
| 19 |
|
| 20 |
.source-item {
|
| 21 |
+
/* display: block;
|
| 22 |
min-width: 100px;
|
| 23 |
+
max-width: 80%;
|
| 24 |
+
margin: 0 auto;
|
| 25 |
height: fit-content;
|
| 26 |
background-color: #febe10;
|
| 27 |
color: black;
|
| 28 |
padding: 5px;
|
| 29 |
text-align: center;
|
| 30 |
border-radius: 5px;
|
| 31 |
+
box-shadow: 0 2px 5px 0 rgba(0, 0, 0,0.2); */
|
| 32 |
font-size: medium;
|
| 33 |
}
|
| 34 |
|
| 35 |
.ssearch-source {
|
| 36 |
+
/* text-decoration: none; */
|
| 37 |
box-sizing: border-box;
|
| 38 |
}
|
| 39 |
|
|
|
|
| 43 |
|
| 44 |
.candid-org-link {
|
| 45 |
font-weight: bold;
|
| 46 |
+
/* text-decoration: none; */
|
| 47 |
}
|
| 48 |
|
| 49 |
.candid-app-link {
|
static/elastic_agent_worflow.jpeg
ADDED
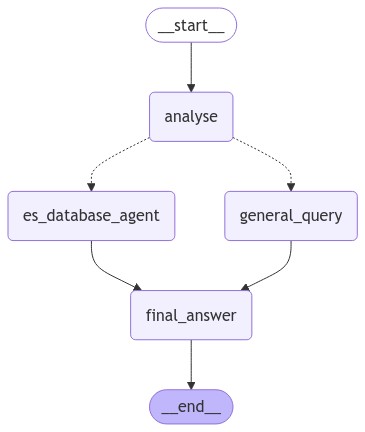
|